





A recent report on VR World provides some new information about Nvidia's Pascal GPU design and the plans the chipmaker has for the technology. At the Japanese GTC (GPU Technology Conference) last month Marc Hamilton, VP of Solutions Architecture and Engineering at Nvidia, closed his GTC keynote with a talk about the future GPUs coming from Nvidia.
Hamilton said that Pascal will be shipping in volume in 2016. He touched upon the most important and unique new features of Pascal, saying it will provide; mixed precision (INT8, FP16 and FP32) and double precision calculations, on board 3D memory and the new NVLink interconnect between GPUs and memory.
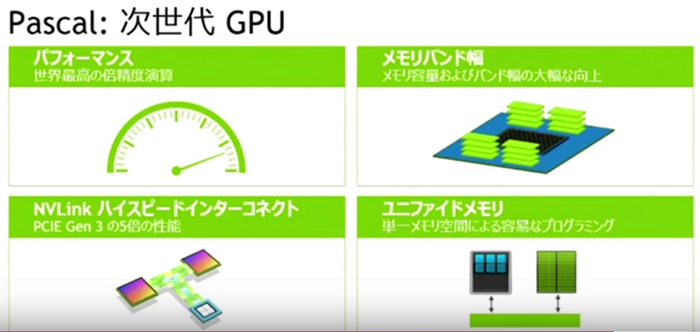
3D memory will improve both memory capacity and bandwidth significantly. With a faster GPU and 3D memory the existing interconnect technology was seen to be 'outdated', so the 5x faster 3D Link interconnect was developed. Nvidia will also support unified memory in its software, providing a single address space for CPUs and GPUs.
Filling in further background detail, VR World confirms that the Pascal GPU will be manufactured by TSMC on the 16nm FinFET process. Pascal will be able to support up to 32GB of HBM2 memory and provide up to 1TB/s of bandwidth, while internally enjoying 2TB/s bandwidth.
The next generation Nvidia GPU will also be made in multi-GPU packaging in all-new Tesla server accelerators. NVLink will enable dual-GPU cards with up to 80GB/s bi-directional interconnects, this should replace PLX PCIe Gen3 bridge chips that can only support 16GB/s (8GB/s per GPU). Newer APIs like DirectX 12 and Vulkan should benefit greatly from the improved memory management and access speeds as we move towards the mainstream 4K PC gaming era.

In other Nvidia Pascal GPU news, The Register reports that the US NOAA agency, involved in weather prediction and related fields, intends to build a new computer boosted by 760 Nvidia Pascal GPUs. The new machine will improve the NOAA Global Forecast System (GFS) grid reference point resolution from 28km to 3km. Increased resolution, more clarity about how weather systems are acting, should simply result in better forecasts.







