





Nvidia has announced a new version of its CUDA parallel computing platform and programming model, ahead of the annual International Conference for High Performance Computing, Networking, Storage, and Analysis in Denver next week (also known, in short, as SC13). CUDA 6 is said to “dramatically simplify parallel programming” by offering programmers unified memory access and also to accelerate applications using drop-in libraries and multi-GPU scaling.

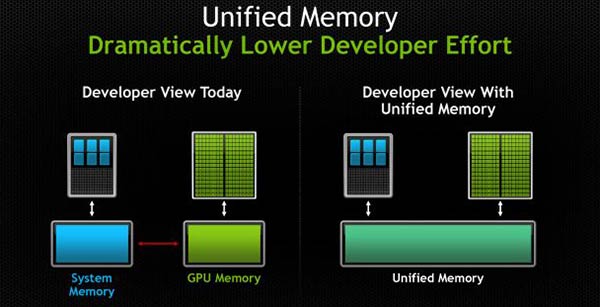
With the latest implementation of unified memory support in CUDA 6 Nvidia has simplified programming “by enabling applications to access CPU and GPU memory without the need to manually copy data from one to the other, and makes it easier to add support for GPU acceleration in a wide range of programming languages”. To be clear this is just a simplification for the programmer; memory copies between the system and GPU memory still need to be done and the latencies remain, however CUDA 6 handles the programming for you transparently.

This simplified implementation should both speed up coding for existing developers and attract new developers. “By automatically handling data management, Unified Memory enables us to quickly prototype kernels running on the GPU and reduces code complexity, cutting development time by up to 50 percent,” attested Rob Hoekstra, manager of Scalable Algorithms Department at Sandia National Laboratories.
Drop-in libraries and multi-GPU scaling are also implemented in CUDA 6. We are told that the drop-in libraries will automatically accelerate “BLAS and FFTW calculations by up to 8X by simply replacing the existing CPU libraries with the GPU-accelerated equivalents”. Multi-GPU scaling is also supported in the new BLAS and FFT GPU libraries. These libraries “automatically scale performance across up to eight GPUs in a single node, delivering over nine teraflops of double precision performance per node, and supporting larger workloads than ever before (up to 512GB)”.
The new CUDA 6 platform will be further detailed next week at SC13 in Denver. The updated CUDA toolkit is expected to be made available in early 2014.







