





At the beginning of the week Intel revealed its Radeon and GeForce-rivalling branding, and promised further details about its upcoming discrete graphics cards for PCs. Today it followed through on that promise at its special Intel Architecture Day event. In the article before this you will have read all about Intel Alder Lake, with details provided at the same event.

Intel ARC Alchemist graphics cards will be the first generation thrust into battle against AMD's RDNA2 and Nvidia's Ampere discrete GPUs. Intel reckons that its ARC Alchemist graphics cards will grasp "leadership performance" by leveraging architecture, logic design, circuit design, process technology and software skills that are at Intel's disposal.

On the topic of the underlying architecture, Intel got more specific, thankfully. Xe-core is described as the compute building block of Xe HPG-based GPUs. In the diagram above you can see a close-up of one of these slices that are all-important to building an Alchemist ARC GPU to target a market segment. Inside each Xe-core there are 16 vector engines (compute focussed), and 16 matrix engines (artificial intelligence focussed).
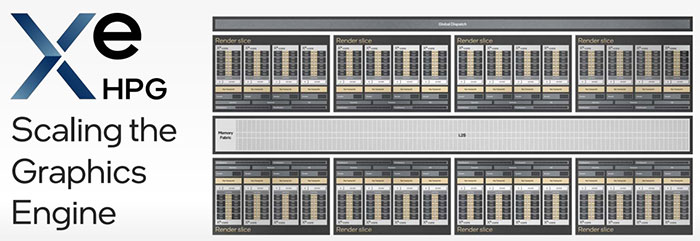
Alongside a certain number of these slices (up to eight) an Xe HPG GPU will add a set of fixed function units optimised for key DX12 Ultimate gaming features, falling into the following categories; geometry pipeline, rasterisation pipeline, samplers, and pixel backends. Then we have a ray tracing unit per Xe-core slice, capable of ray traversal, bounding box intersection, and triangle intersection calculation acceleration. Last but not least, Intel adds a chunk of L2 cache to fit the target segment of the GPU.
Key official features of the Alchemist SoCs, based on the Xe HPG, will be as follows:
- Up to eight render slices with fixed function designed for DirectX 12 Ultimate
- New Xe-cores with 16 vector engines and 16 matrix engines (referred to as XMX – Xe Matrix eXtensions), cache and shared local memory
- New ray tracing units with support for DirectX Raytracing (DXR) and Vulkan Ray Tracing
- 1.5x frequency uplift and 1.5x performance/watt improvement compared with Xe LP microarchitecture through a combination of architecture, logic design, circuit design, process technology and software optimizations
- Manufactured on TSMC’s N6 process node
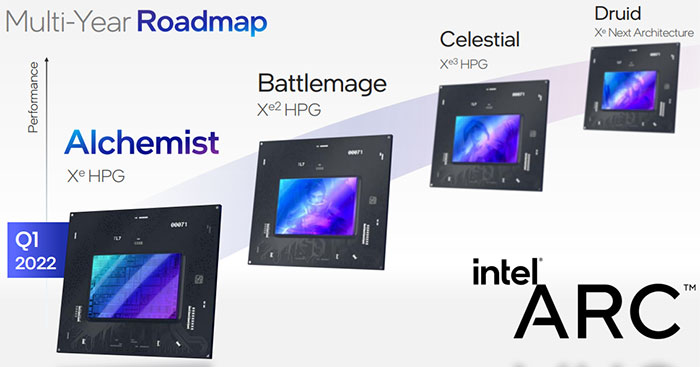
As a reminder, from Monday, the client roadmap starts with Alchemist in Q1 2022, but will progress Battlemage, Celestial and Druid SoCs.

Xe HPC and Ponte Vecchio
Intel also wanted to shine light on its Xe HPC architecture for data centres, which it claims "delivers industry-leading FLOPs and compute density to accelerate AI, high performance computing (HPC), and advanced analytics workloads". GPUs based upon Intel Xe HPC slices are codenamed Ponte Vecchio.

Like with Xe HPG the Xe HPC GPUs will be made from various slices mixing vector engines, matrix engines, caches, and raytracing units in slices – but here the density is increased in stacks and Xe-Link high speed fabric is used to build bigger GPUs – all placed on a base tile for scalability using Intel Foveros Technology. Of course, with the different tasks of importance to data centres the Slice ingredients are different to get the optimal performance from the silicon, as well as offering more scalable options.
 |
 |
 |
Intel demonstrated Pone Vecchio A0 silicon providing 45 TFLOPS FP32 throughput, greater than 5TBps memory fabric bandwidth and greater than 2TBps connectivity bandwidth. It also showed a demo of Ponte Vecchio powering ResNet inference performance of over 43,000 images per second and greater than 3,400 images per second with ResNet training – claimed leadership figures.








