





According to sources on the Beyond3D and 3DCenter forums Nvidia's next-gen Pascal GPU has been taped out. Thus the first of the Pascal architecture chips, known as the GP100, has successfully been prototyped using the TSMC 16nm FinFET Plus process. This is a significant milestone and now engineers will be able to test and tweak the design to ready it for market rollout.
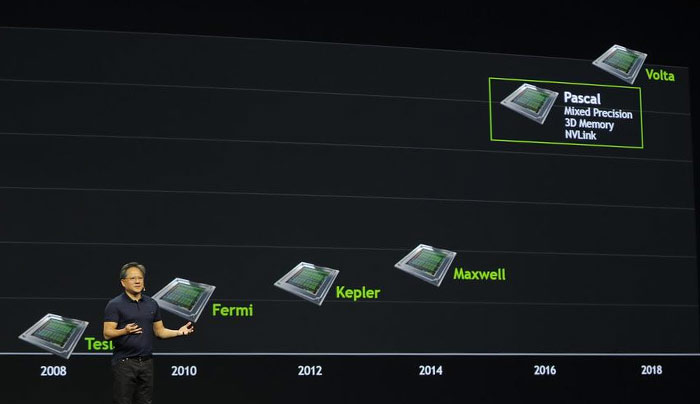
As trailed by Nvidia, at its GTC Keynote this March, the Pascal GPU will be "10X faster than Maxwell". While that was admittedly a rough high-level estimate, and applied to niche purpose 'deep learning' calculations, it does at least sound like a very significant performance jump. In more general perfromance terms the Pascal architecture will implement three important new features:
"One is mixed precision, which is provides at 3X the level of Maxwell. Another is 3D memory, which provides more bandwidth and capacity simultaneously. A third is NVLink, which is an ability for multiple GPUs to be connected at very high speeds. It also has 2.7X more capacity than Maxwell."

The 3D memory that Nvidia refers to above is believed to be the latest HBM2 type, it boasts of a maximum memory bandwidth of around 1.2TB/sec. We have heard that AMD plans to move onto using HBM2 in its graphics cards next year sometime but perhaps Nvidia will get there first as the Pascal GP100 GPU could be launched as early as Q1 2016.

The Beyond3D source suggests that the GP100, successor to the GM200, could mark a return of the 'big die first strategy' where the first chip from the emerging architecture will be designed for professionals/high end. The enthusiast and performance level GP104, successor to the GM204, is expected a quarter or two later, in Q2/Q3 2016.
Specifications of the Nvidia GP100, according to 3DCenter, will be more-or-less as follows:
- speculative: ~ 500-550mm² chip area
- speculative: 4500-6000 shader units
- speculative: 4096-bit DDR memory interface HBM2 (HBM2 interface factually certain)
- confirmed: up to 32GB HBM2 memory (Gamer variants probably only 16 GB)







