





It is no secret that AMD is gearing up to launch cutting-edge GPU (Vega) and CPU (Zen) architectures in the coming months. At an event in Sonoma, California, last week, AMD changed gears by announcing a new line of graphics accelerators and accompanying open-source software for the burgeoning field of machine learning. This strategy, which is to augment its traditional strengths in gaming graphics and CPU processing, goes by the name of Radeon Instinct.
The huge parallel processing ability, or compute performance, of GPUs is an ideal fit for machine learning, AMD says, and it's a necessary and much-needed field in the face of the incredible amount of data being generated on the net. Put simply, our ability to gain meaningful insight from quintillions of bytes per day is compromised by a lack of adequate analytics. This is a big-data problem in the truest sense, and it is only going to become harder to solve as billions more sensors enter the 'net ecosystem through the rise of Internet of Things (IoT).

This is where machine learning comes in, and it touches practically every facet of modern technology. In its most basic form, machine learning, a type of artificial intelligence, uses algorithms that learn to recognise patterns in data and then apply these learnings to subsequent, new data without having to be explicitly programmed to do so. Iterative improvements and understanding through pattern recognition, if you will. The machine-learning concept isn't new, of course, but given the extreme amount of data being produced, it is becoming vital to separate the wheat from the chaff in order to make sense of it and extract what you really need.
It just so happens the explosion in data has coincided with magnitudal increases in distributed compute power (teraflops on single GPUs) and rise of inexpensive storage. This is why AMD believes the time is now for machine-learning-centric Radeon Instinct.

So, to address the incumbent problem and huge opportunity within the sphere of machine learning - both time-consuming training the and easier inference - AMD is announcing three GPUs primed for the purpose. The first, MI6, is based on Polaris architecture, the second on Fiji, while the most interesting one, MI25, uses the as-yet-unrevealed Vega blueprint.
The trio of passively-cooled cards, built exclusively by AMD and featuring advanced virtualisation capabilities, bear a striking resemblance to present FirePro S-series cards, also passively cooled, albeit now presented in different design livery. The MI6 - great name, huh? - is the Radeon RX 480 shoehorned into professional guise. Almost 6TFLOPS of performance and a sub-150W TDP match up well with the gaming card's credentials, though this model has 16GB of onboard memory suitable for larger datasets. It's a good fit for the inference part of machine learning, AMD says.
The second, MI8, looks a lot like the Radeon Fury Nano from an architecture, TDP and throughput perspective, and AMD says it offers a decent balance between computational-heavy training and inference elements of machine learning.
Far more intriguing is MI25. Notice how these cards' names match up reasonably well with their TFLOPS throughput. If that naming convention holds true, the Vega-powered MI25 offers a staggering 25TFLOPS of compute. Yet before you salivate and think of what this could mean for gaming in, perhaps, RX 490 form, we can tell you that such a figure is based on half-precision throughput (16-bit). Vega, as you will learn, offers more mixed-precision ability than ever before, and specific to machine learning, enhanced floating-point accuracy is not always required.
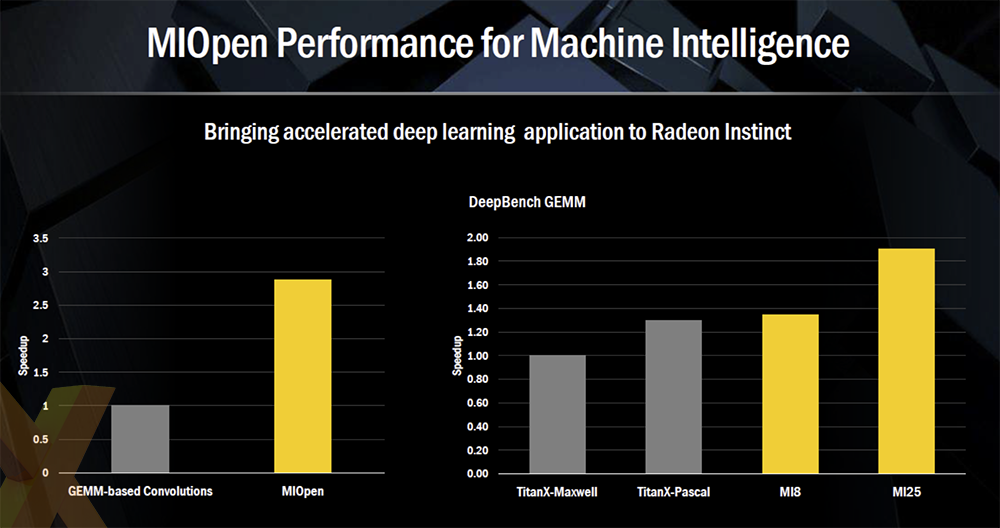
AMD is acutely aware that hardware excellence is only one part of the equation. 'AMD has packed more compute, per square mm, per dollar, than the competition, for the last 11 years,' said Raja Koduri, chief of the Radeon Technologies Group. This is why AMD has also announced a full deep-learning, open-source software library, called MIOpen, to support these processors.
Offering up to a 3x speed-up when running the same applications on common GPU-addressing frameworks such as OpenCL or Cuda, MIOpen means that the MI8 is faster than Nvidia's Titan X (Pascal) while the Vega-powered MI25 is 50 per cent faster still on the DeepBench benchmark. Koduri indicated that he expects performance to increase further as Vega is optimised. Indeed, giving credence to how he views MIOpen, Koduri went on to say that 'the most important part of our strategy is the software stack (MIOpen).'

MIOpen fits into the larger virtualisation-aware ROCm software ecosystem, which is AMD's take on Nvidia's Cuda. You may know that, on a lower level, HIP is used to translate Cuda code to run on Radeon GPUs. This means machine-learning frameworks such as Caffe, written in Cuda, are now available to GCN-powered GPUs - AMD says the port took just a few days, and, pragmatically, this is where the real money is.
Koduri went on further to say that AMD is providing full virtualisation capabilities across the full Radeon Instinct stack, thus indirectly having a swipe at how Nvidia segregates its professional business, from Grid to Tesla, by offering different feature-sets on each.
What we take away from our time with AMD is that it is serious about the opportunities around machine learning. The company knows that GPUs are ideal for the task, and while it has already acknowledged that hardware isn't a problem - Vega looks suitably impressive - it needs to match, or exceed, Nvidia in the supporting software. MIOpen, a part of ROCm, appears to have potential.
Yet time will tell if AMD's software can really pull out the compute goodness contained in the latest slew of hardware, and whether developers embrace it as the company hopes. If these key aspects turn out to be true, Radeon Instinct may well become a source of solid revenue for the red team.







