





Earlier this week we saw an interestingly edited version of the Intel process roadmap. At the IEEE International Electron Devices Meeting Intel semiconductor machinery partner ASML presented a previously unveiled roadmap but with nanometer node sizes overlayed on corresponding years. Thus, for the first time, we saw the goal of the introduction of 1.4nm processors associated with Intel, and they are expected sometime in 2029.
The advancement highlighted is that of monolithic scaling, where reducing transistor feature sizes, and operating voltages, results in transistor performance increases. However, as hinted at by the likes of Jim Keller previously, Intel will be mounting at least a two pronged attack on processor performance advancement using other means.

Robert Chau (pictured above), Intel Senior Fellow and Director, Components Research, has just shared a blog post about Intel's efforts in both monolithic scaling and system scaling. At the recent IEDM, Intel researchers presented nearly 20 papers on advancing Moore's Law and Chau wanted to summarise some of the approaches he sees paying off over the next few years.
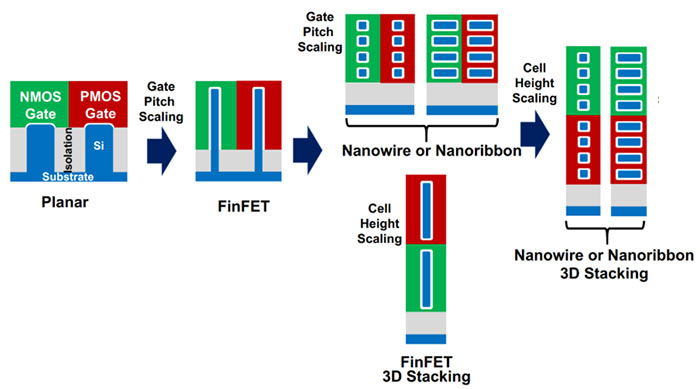
With regard to the monolithic scaling, Chau talks about the planned advancement from FinFETs to Gate-All-Around (GAA) FETs. What you need to know is that GAAFETs, from skinny nanowires to wide nanoribbons, hold the potential to "pack more high-performance transistors into a given area, thus reducing the width of the standard cells our designers use to build new processors". Additionally, stacking FinFETs, GAAFETs, or even a combination of both are techniques that may pay dividends in advancing processor efficiency.
Further monolithic scaling advancements can be had from the use of multiple materials alongside silicon. Chau mentions substances like germanium and gallium-nitride being demonstrated as complementary to silicon in squeezing out more performance in smaller packages.
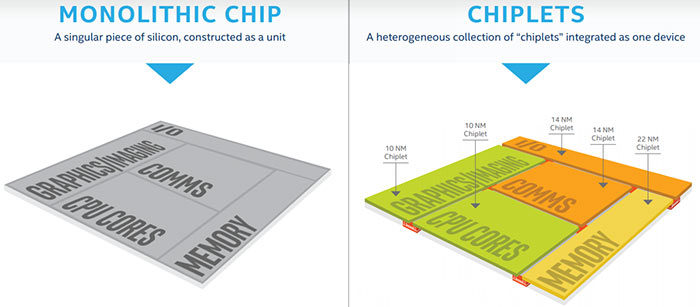
Intel is also looking at system scaling - finessing designs beyond the transistor level. Chau recounts how a decade ago SoCs were put together simply to add GPU and I/O functionality in the same die as a high-performance CPU. Now the art of this integration has become a greater emphasis for processor designers. "This type of dis-integration may seem, at least initially, to be the antithesis of what Moore's Law is intended to accomplish," observes Chau. "But the performance and density improvements gained by matching each type of processor to its own best-fit transistor logic and design implementation often outweigh the negatives caused by separating a monolithic die into smaller chiplets."
Already, Intel EMIB interconnect technology is being fused with Foveros tech to produce Co-EMIB. Intel claims that "Co-EMIB allows for the interconnection of two or more Foveros elements with essentially the performance of a single chip." Using Co-EMIB designers can connect analogue, memory and other tiles with very high bandwidth and at very low power.
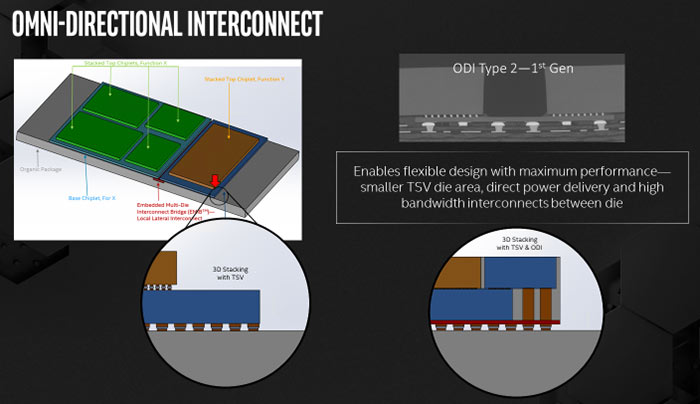
However, Intel is already looking beyond Co-EMIB at a new standard called Omni-Directional Interconnect (ODI, see image above) which uses much thicker through-silicon vias for better power delivery, as well as other refinements.
Summing up, Chau highlights the intention that classic, exclusively transistor-focused, advancements in Moore's Law will be given a leg-up by tech such as 2D stacking and ODI to deliver meaningful generation-on-generation improvements in both density and performance. Finally, Intel's unique status as an integrated device manufacturer (IDM) is an advantage - as its closely communicating design teams and fabrication engineers can "tweak an architecture to better match the capabilities of a process node, or to fine-tune a node to match capabilities we want to deliver in a given architecture". Chau signs off by saying that he has never been so optimistic about the long-term health of Moore's Law as he is now.







