





Intel P4 2GHz
Introduction 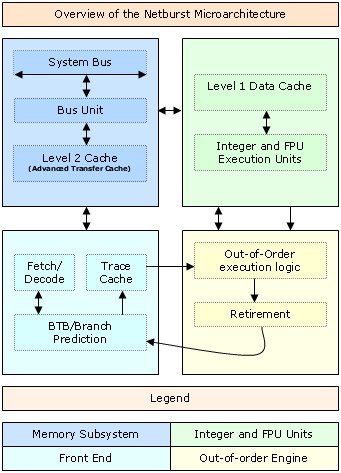
As you can see, Netburst is made up of 4 main sections, each interacting with each other to provide the core of the processor. Lets take a look at them in turn. The in order front end is the first port of call for instructions entering the processor pipelines. It function is to get the instructions next in line to be executed (Fetch) from the branch predictor and decode them into the micro ops the other units understand (Decode). The branch predictor is the logic responsible for deciding what part of programs are likely to be executed next. The Fetch/Decode unit then feeds the decoded micro ops into a very small Level 1 Trace Cache. The Trace Cache is a high speed cache for the decoded micro ops that are fed to the next stage, the out-of-order execution logic. The out-of-order execution engine first attempts to grab its micro ops from the Trace Cache and if the processor is doing a good job, the ops are there and the Fetch/Decode unit isn't brought into play, wasting clock cycles, increasing performance. However if the required micro ops aren't available in the Trace Cache, the Fetch/Decode unit is brought into play and starts the process again. The Out-of-Order logic is responsible for reordering (often very aggressively) the micro ops as it feeds them to the execution pipeline. It works to keep the pipeline as busy as possible since idle time in a 20-stage pipeline is costly in terms of performance as an idle period may take up to 20 cycles to clear, longer if it's idle for a greater time. The logic can keep instructions to be executed following a busy state ready to go as soon as the input data is ready minimising stalling while a micro op waits for its input data. Finally, it also reports back to the branch predictor with branch history information so the predictor is up to date with the current data flow and can make better decisions about what needs to come next. The execution units, ALU and FPU, are where instructions are finally executed. They are split up into different sub units that perform different kinds of calculation and this section of the CPU is also home to the L1 cache where data is stored and loaded from whilst performing the calculations in the units. It's worth noting that the ALU unit runs at twice the external CPU frequency. In our 2Ghz test CPU the unit runs at 4Ghz. Finally we have the L2 Cache, used to hold everything that doesn't fit in L1 and the Trace Cache and its interface to the main system bus and onto main memory which it can access when required. It's the final piece in the Netburst puzzle. That's Netburst somewhat simplified and I hope easy to follow. The architecture hasn't changed yet but it's expected that Intel will add hyper threading to Netburst at some point. You can read about Hyper Threading here. As a quick overview it creates two logical processors on one CPU die and it can do this because of the parallel design of the architecture. There isn't enough scope to go over it here, but please explore it further because it will appear on an Intel CPU near you in the future. Performance So we've seen the architecture, how does it translate into real world performance. We'll take a look at the usual stuff here, Sandra, 3DMark 2001 Professional and our old friend POVRay. First off, the usual Sandra CPU benchmarks in both CPU Arithmetic (stressing the execution units we talked about previously) and CPU Multimedia performance (performance when running SSE2 code). CPU Arithmetic Benchmark 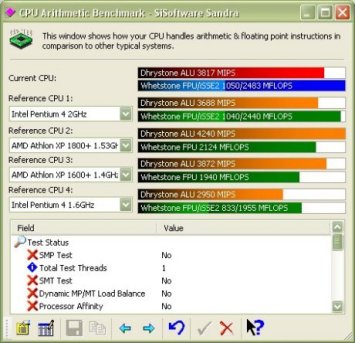 CPU Multimedia Benchmark 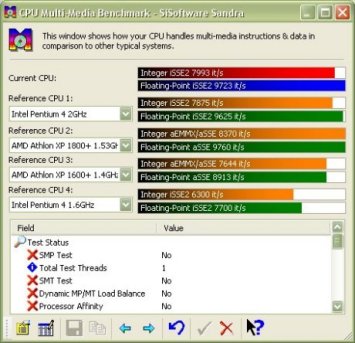 As we can see, the 2Ghz P4 is pretty much neck and neck with the XP1800 in these benchmarks. With those two processors it's hard to choose a performance winner. However with AMD having released XP1900 and now XP2000, the 2Ghz Pentium 4 struggles to beat the current AMD pinnacle in terms of pure speed. However Intel have recently, within the last couple of days, released new processors which hope to wrestle the performance crown back. Memory bandwidth when running with i850 based boards has always been high with the Pentium 4 processor. RAMBUS RDRAM is high bandwidth but also quite high latency at current speeds. Latency actually goes down the quicker you go with RAMBUS but at the moment 3.2Gb/sec with relatively high latency is only slightly faster than 2.1Gb/sec from DDR266 DDR SDRAM which has very low latency. Here's an example of the kind of result Sandra will give you when running on the P4X266, VIA's DDR chipset. Note the comparatively low i850 result. The run was done on a pre release Sandra for which the reference numbers hadn't been updated yet. Not as fast as i850 and RAMBUS ultimately but the low latency is a real world performance improvement and the P4 has the luxury of both memory architectures. 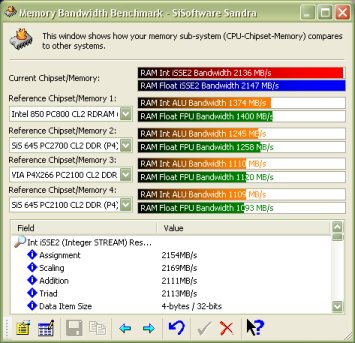 Finally we have POVRay. POVRay is a ray trace renderer that renders a scene by calculating the light rays from any light source in a scene, calculating how they will look when they hit the scene objects. Given that it calculates many light rays per scene, the render is incredibly CPU intensive and is a true test of CPU speed in the real world. We use the pawns.pov scene available in the standard POVRay distribution and optimised P3 and P4 binaries available from the POVRay Recompilation Experiment. The P3 binary typically runs faster on an AMD AthlonXP however the P4 binary, optimised via a compiler for the P4 processor runs much faster. The results are from the exact same scene and render string, only the binary changes here.  As you can see, a simple switch the the P4 optimised binary gives a 9 second speedup rendering the same scene which equates to a 23.6% speedup in rendering time. All that has changed is the compiler that compiles the source code which has P4 optimisations turned on. As application vendors and software developers migrate their compilers, slowly but surely like for like performance on the processor should increase. Overclocking Being an Engineering Sample processor, it was quite easy to overclock given that the full range of multipliers and FSB speeds were available. Being able to choose the multiplier on a P4 is a god send since the high multiplier of the stock 2GHz Pentium 4 at 20x can become a problem. The maximum overclock we achieved on the processor came on the MSI 845 Pro2 i845 motherboard. Using a GlacialTech Igloo 3200 heatsink the multiplier was dropped to 16x and the FSB pushed up to 144Mhz before the limits of the cooling gave way and the processor became unstable. 2.3Ghz air cooled is quite an achievement and the processor would surely go much higher in a Vapochill or similar low temperature cooling. Before we conclude things, let's take a quick look at the CPU Arithmetic run in Sandra and a WCPUID shot for proof. 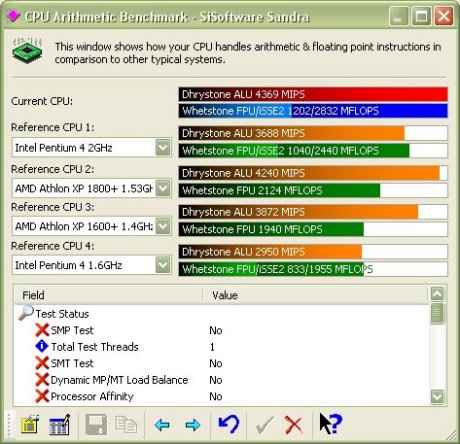 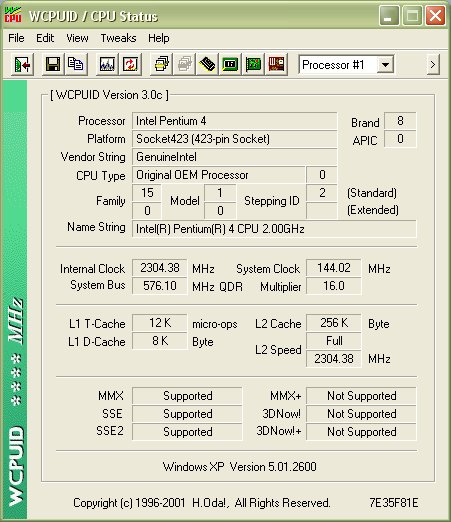 As we can see, a 2.3Ghz P4 easily beat the XP1800 in our Sandra benchmarks and would beat the XP1800 and XP1900 and is pretty much neck and neck with the XP2000. Real world performance on the 2.3Ghz overclocked setup was very fast due to the high CPU clock, overclocked FSB (giving an overall system boost). Conclusion We've taken a look at the processor, seen a few benchmarks both at stock speeds and overclocked and taken a close look at the architecture. As we can see, the P4 performance really starts to kick in at high clock speeds. The architecture was designed for this and we shall hopefully see Intel aggressively ramp up the clock speed in 2002. They've started this with the 2.2GHz Northwood processor just recently released. The deeply pipelined processor (20 stages) is designed to be fed data extremely quickly for it to work to maximum efficiency. The addition of Hyper Threading will further boost the performance. All the processor needs is clock speed and hopefully we'll see that soon. Price on the 2Ghz has naturally taken a nose dive recently and from the heady heights of being a £600+ piece of silicon it it now in the mid to low £300 range. AMD's top of the range processor isn't that much cheaper. However the new 2.2Ghz P4 has debuted at £600+. The 2Ghz is now interesting for those lucky enough to spot one on the 2nd hand market so good luck finding one at a decent price. Excellent performance when combined with either DDR or RDRAM memory with only the price making things awkward and the test processor at least was a fine overclocker. Not quite fast enough to topple the XP2000 but a strong performer all the same and should satisfy anyone's thirst for CPU horsepower. |







