





Bristol-based Graphcore has just launched its second gen IPU (Intelligence Processing Unit) systems which are targeting organisations which wish to do AI processing at scale. Inside these IPU-Machine M2000 1U blade systems are four of the new Colossus MK2 GC200 IPUs built by TSMC on its state of the art 7nm process and packing 1,472 cores each and capable of "one PetaFlop of Machine Intelligence compute". If an IPU-Machine M2000 sounds like something you would like to expand upon, Graphcore has introduced the IPU-POD which can facilitate datacenter-scale systems of up to 64,000 IPUs, delivering up to 16 ExaFlops of Machine Intelligence compute.

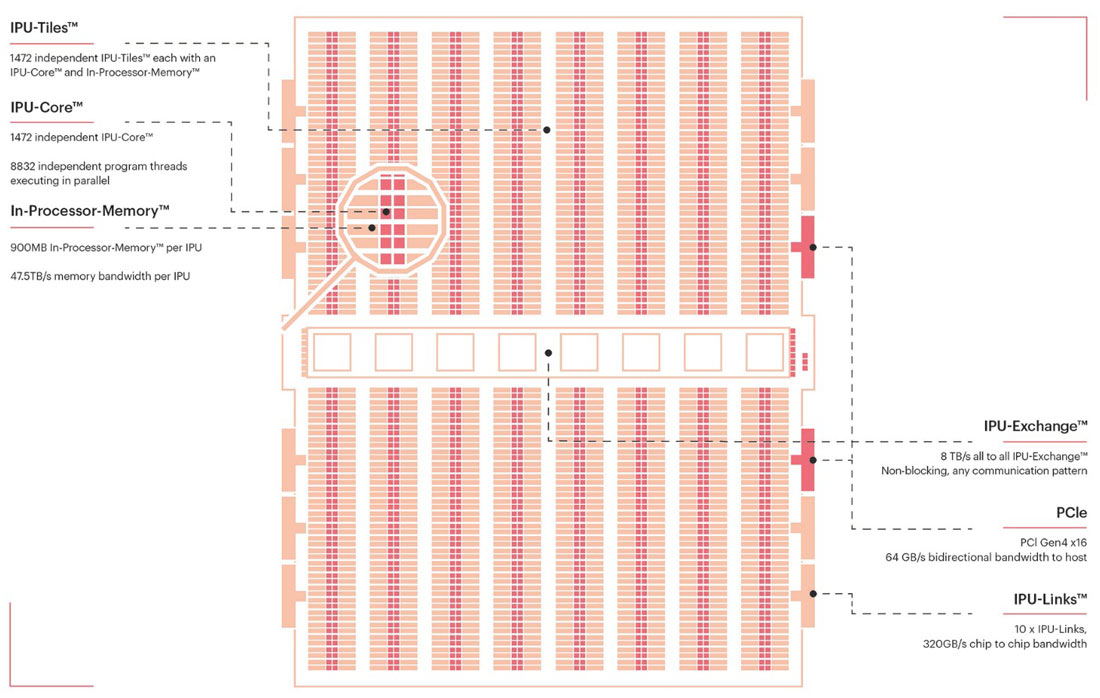
Let us start by looking more closely at the processor that is central to all of today's announcements, the Graphcore Colossus Mk2 GC200 IPU. The key specs and features of this processor can be seen in the main diagram and I have bullet pointed them below for greater clarity.
- 59.4 billion transistors per IPU,
- TSMC N7 chip is 823mm² in size,
- 1,472 IPU-Cores each with and IPU core and in-processor memory,
- 8,832 separate parallel computing threads,
- 900MB SRAM per IPU,
- 47.5TB/s memory bandwidth per IPU.
Graphcore says that its second gen IPU was built from the ground up using the Poplar SDK to accelerate machine intelligence. The new IPU surpasses the performance of its first gen chip (2018) by 8x in real-world tests.
The Graphcore IPU-Machine M2000 1U blade uses four of the GC200 IPUs in a pizza box size system to deliver 1 PetaFlop of AI compute. This system puts 5,888 processor cores and 35,328 independent threads at your disposal, as well as up to 450GB of off-processor streaming exchange memory.

Moving up to supercomputer scale machine learning processing and Graphcore says it has this covered too. Its IPU POD64 building blocks help you deploy thousands of machines for large AI/ML problems or multiple concurrent workloads. Graphcore says it features ultra-high bandwidth, low-latency communication, enabled by its own IPU-Fabric technology.

The above might be academically interesting but I bet you are wondering how systems packing 7nm Graphcore Colossus Mk2 GC200 IPUs face off against the likes of Nvidia DGX A100 systems? Graphcore shares a comparison slide where EfficientNet-B4 image classification is compared. For the same performance, it asserts you would need only invest $259k in Graphcore systems, rather than >$3m in Nvidia DGX-A100 servers.

Availability
IPU-Machine M2000 and IPU-POD64 systems are available to pre-order immediately with full production volume shipments starting from Q4 2020. Early access users will be able to evaluate IPU-POD systems via Graphcore partner Cirrascale.







