






Intel's datacentre strategy is best encapsulated by a three-pillar approach that takes a holistic look at the challenges facing customers in an ever-connected world. Hardware and software is built to serve the needs of moving, storing and processing data in the most efficient way possible. This may well sound like polished marketing blurb, but it really is the way in which Intel positions itself of late. Recent datacenter-specific acquisitions serve to bolster one or more of these pillars.
This is also why the company has shied away from putting single-minded focus on just the Xeon line of CPUs - though AMD's impressive EPYC chips have plenty to do with that - and is eager to talk about the overall hardware and portfolio breadth. Such thinking is particularly relevant right now as Intel releases a number of AI- and analytics-optimised products and software for 2020.

Intel is betting a large portion of the upcoming datacentre house that demand for artificial intelligence (AI) processing will be a key driver for overall growth. AI is a broad church that requires optimised silicon in a number of areas - CPU, GPU, VPU, FPGA - all tied together with a common software framework enabling simpler heterogeneous compute.
Attention is sure to be fixed on what's being announced right now so let's start with the 3rd Gen Xeon Scalable processors.

It's worth understanding where these Xeons fit into the roadmap, which has been constantly evolving as Intel continually weighs up a number of architectures, manufacturing challenges, and the competition. A huge range of 2nd Gen Xeon Scalable are available right now, equipped with up to 56 cores each on the 9200-series though limited to 28 cores on the more common, socketed 8200-series. These provide great flexibility as they span from one to eight sockets on a single platform.
Today's announcement is for a slew of 3rd Gen Xeon Scalable chips codenamed Cooper Lake whose truncated launch window and limited-SKU release speaks volumes about how Intel executes Xeons in 2020. Key fundamentals remain the same as incumbent 8200-series, translating to a maximum (disclosed) 28 cores and 56 threads per processor, 14nm production, but, crucially, Cooper Lake requires a new platform known as Cedar Island because the chips harness an LGA4189 Socket P+ interface rather than LGA3467 presently.
The timing of Cooper Lake means it's a niche, premium, stop-gap solution of sorts. Why? Because it's only officially available in boards supporting either four or eight sockets rather than the more common 1S/2S that make up the bulk of the Xeon market. That's not to say someone won't try to shoehorn Cooper Lake into custom dual-socket solution, however. Intel's four-and-up reasoning is due to the next-generation Xeons, codenamed Ice Lake, built on the leading-edge 10nm process with a new architecture, also coming in this year on LGA4189 and replacing incumbent Cascade Lake in the volume 1S/2S space. 2020, therefore, is a mix-and-match year for Xeons.
Full-on socket breadth is restored with Sapphire Rapids next year, and Intel has just divulged that silicon has successfully powered on, intimating that a 2021 release is more likely than not. Conjecting somewhat, Sapphire Rapids ought to use the Willow Cove core, 10nm++ production node, and DDR5 memory.
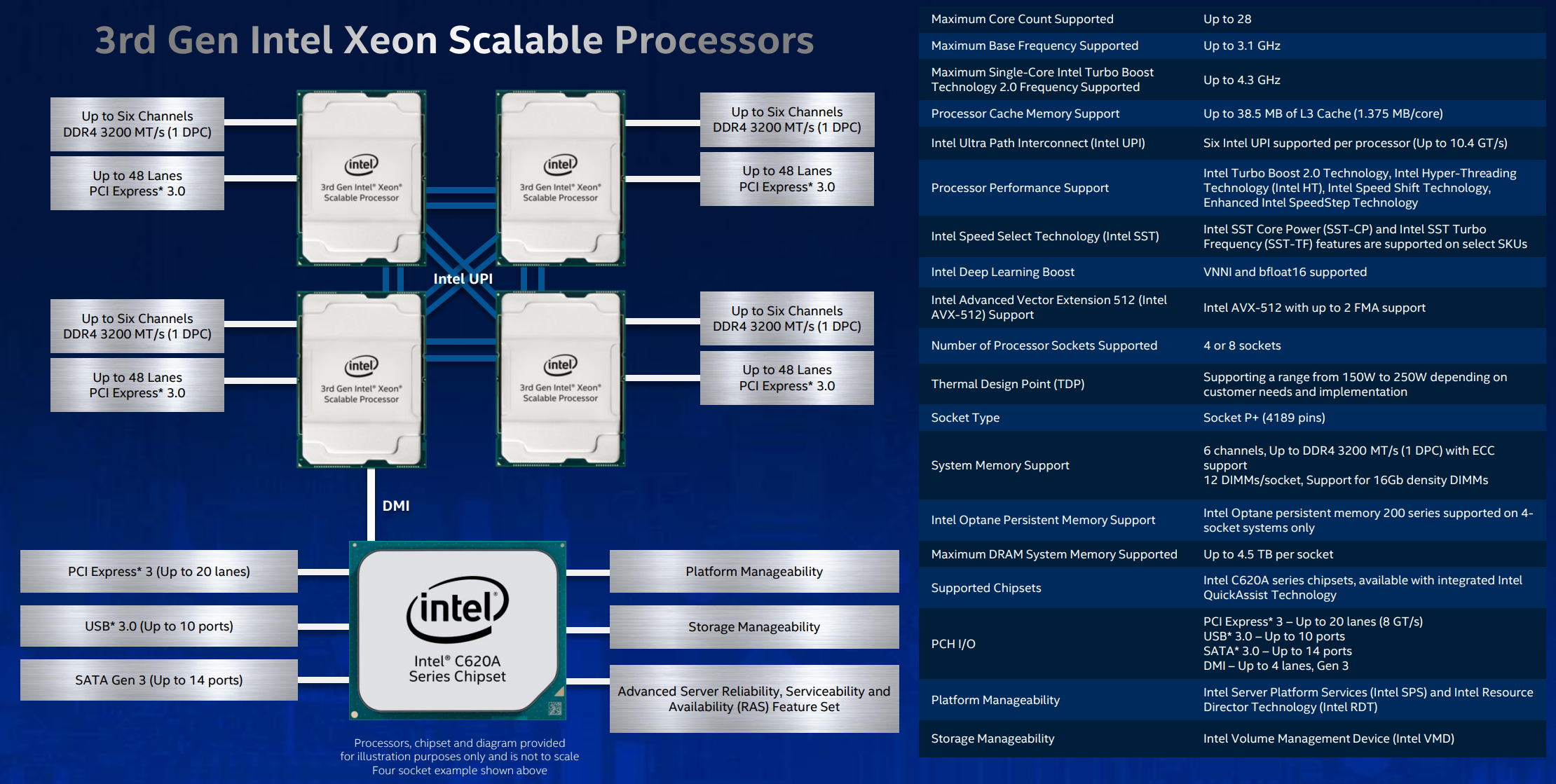
Back to the present, a high-level overview shows these 3rd Gen Cooper Lake Xeons use ostensibly the same architecture blueprint as current models. Process, cores, cache sizes, interconnects, memory channels and capacity, Optane support, and up to 8-way processing are all replicated.
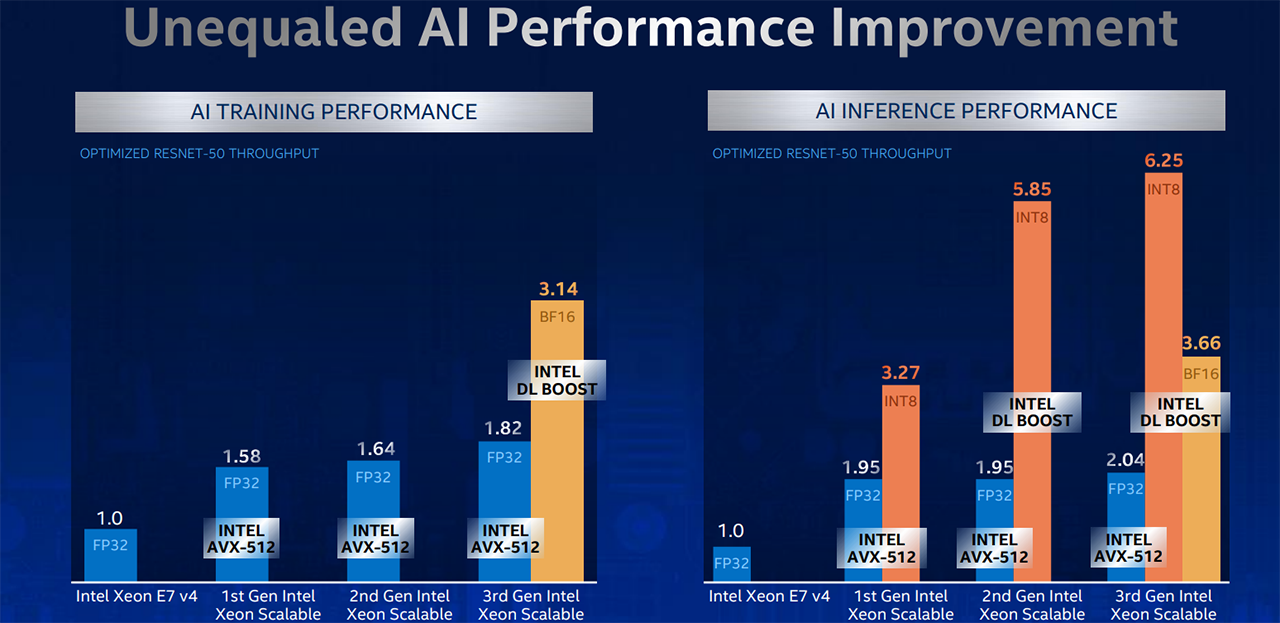
So why even bother, you might ask? A standout feature for Cooper Lake is its additional focus on AI acceleration that comes under the Deep Learning Boost umbrella. Though it's not a big deal on the spec sheet, the introduction of bfloat16 is a feature Intel is excited about.

Bfloat16 offers significant speed-ups in data workflows where rigorous floating-point accuracy is not necessary. It just so happens one doesn't need FP32 accuracy for AI tasks such as training and even less so for inference. It's by lowering the amount of calculation that optimised accelerators are able to process incredible amounts of data, and it's something Intel wants to bring into the fold for general-purpose CPUs starting with Cascade Lake and expanded here.
To that end, bfloat16 is a halfway house between high-speed INT8 primarily used for inference and standard FP32. In technical terms, it keeps the 8-bit exponent (range) of FP32 but reduces the mantissa (accuracy) by 16 bits, which is more than enough for AI. This means that whilst Cooper Lake-infused Xeons chips are marginally faster than equivalent Cascade Lake processors for FP32, by dint of higher peak frequencies, one would assume, they're much quicker for burgeoning AI workloads. Intel likes to trumpet this feature as it is something that rival AMD EPYC chips do without.
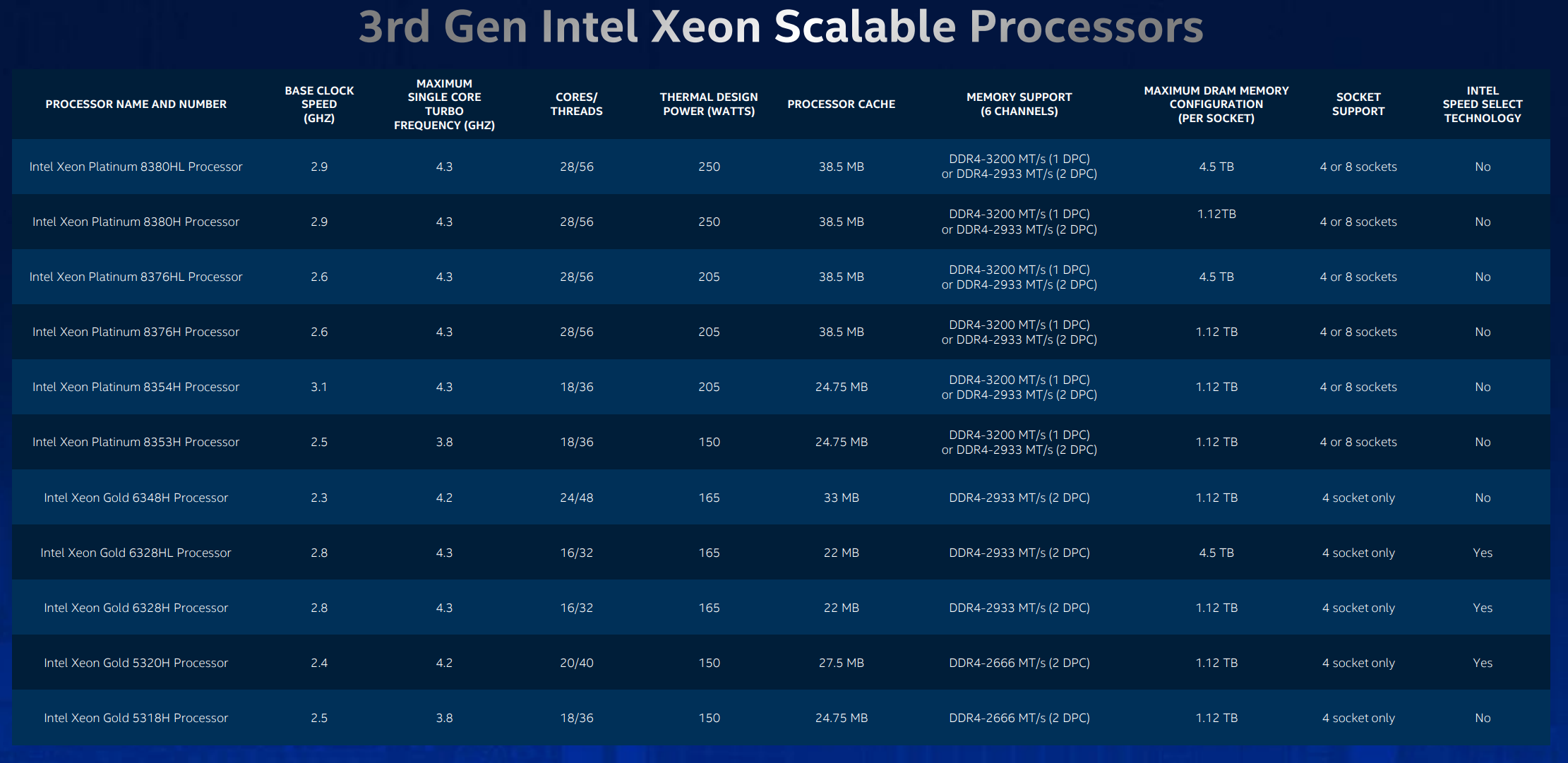
Here's a list of 11 SKUs at launch. We see a new 250W TDP for the top-bin duo alongside higher peak turbo frequencies when compared with the Cascade Lake predecessors. Some feature second-generation Speed Select Technology for enhanced per-core frequency customisation, too. There's also a minor DDR4 memory frequency boost to 3,200MHz if running only one Dimm per channel.
Overall, then, 3rd Gen Xeon Scalable processors, formerly known as Cooper Lake, prioritise high-end, volume customers whose workloads benefit from specific AI acceleration. Pricing may not be disclosed as these chips will most likely be sold in customised chassis for the likes of Alibaba, Tencent, et al.
Whilst Intel bolts faster AI processing onto these Xeons, it appreciates that certain customers need silicon that's much faster for sheer computing than general-purpose CPUs but more programming-friendly than totally dedicated hardware such as Asics. This is where FPGAs fit in, and the Stratix 10 line was born from the acquisition of FPGA specialist Altera in 2015.
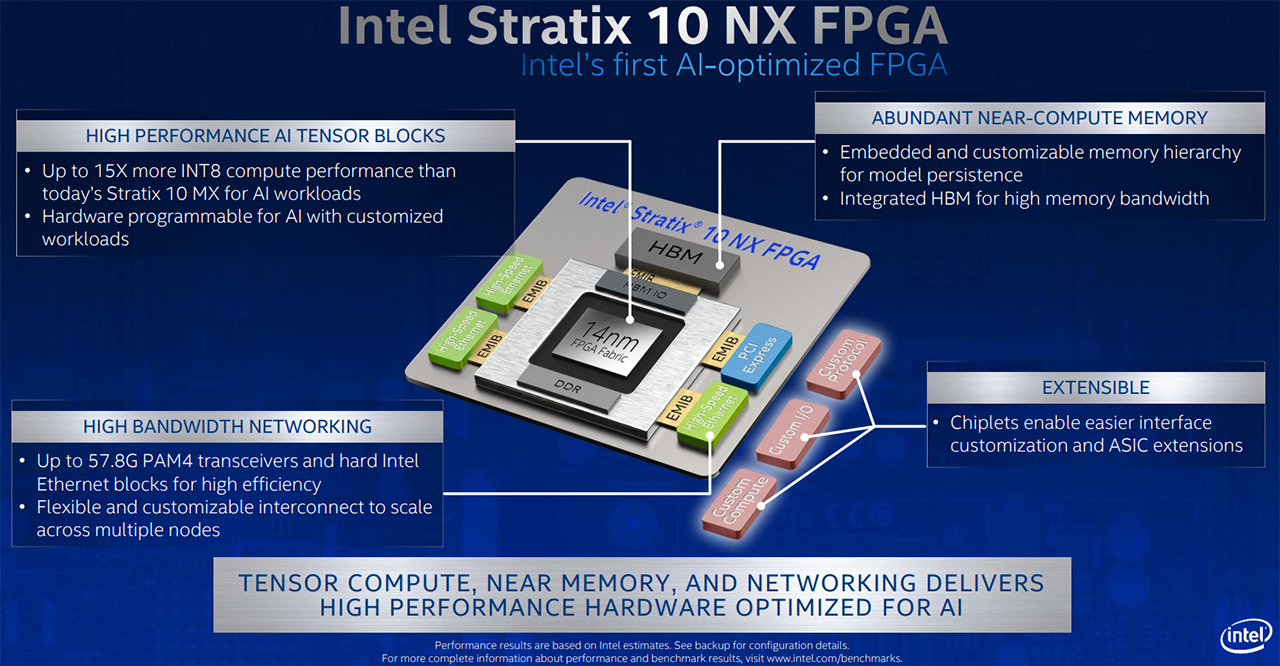
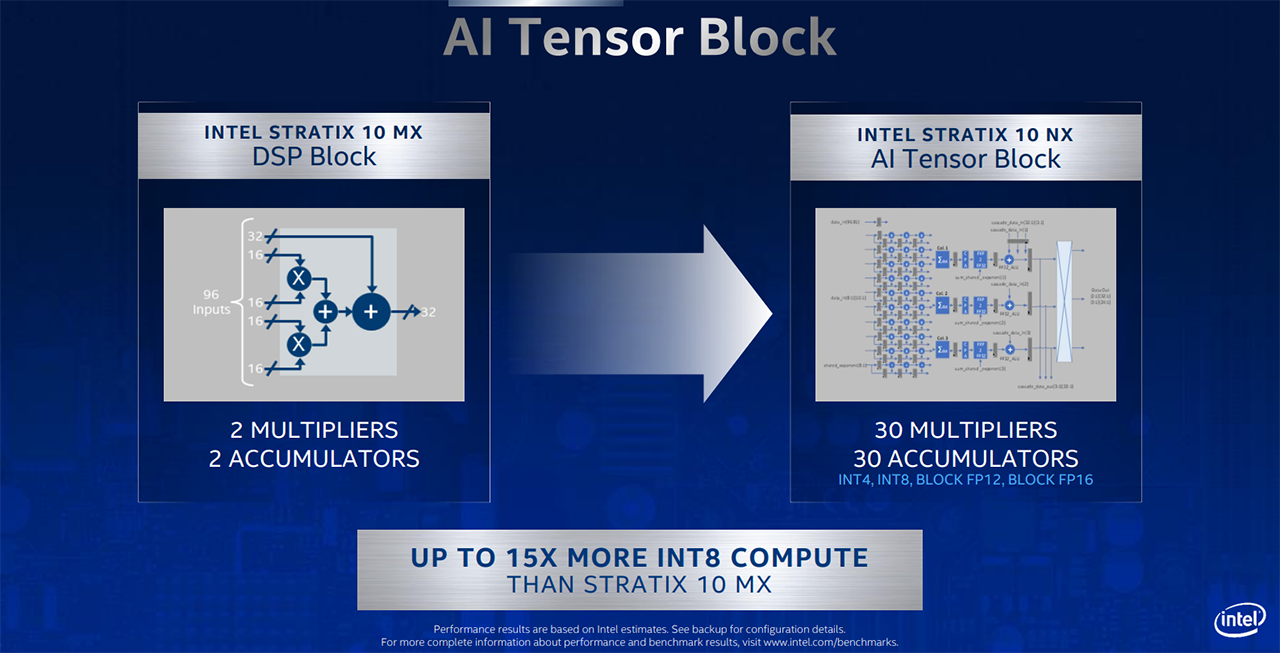
Announced today, the AI-optimised Stratix 10 NX FPGA offers up to 15x more INT8 performance than the present Stratix 10 MX DSP. As we have alluded to, INT8 is a key driver for inference performance in particular, and the massive speed-up has been achieved by building a Tensor Block architecture whose sole aim is to populate the FPGA with as many low-level multipliers as possible - AI work is effectively done by a huge number of calculations on matrices - it's a giant calculator of sorts. HBM memory holds AI models near the compute engines while low-latency data movement is provided by the high-bandwidth networking.
Available later this year to customers, Intel is bullish on the Stratix 10 NX's prospect, citing wide-ranging AI performance in excess of Nvidia's V100. Time will tell if the facts are borne out by real-world performance.
In summary, Intel is going big on AI this year through specific hardware features on limited-run Cooper Lake 3rd Gen Xeon Scalable processors and its first AI-optimised FPGA chips.








{kind=link}
{kind=link}