





Bringing Balance to the GeForce
AMD stole a march on Nvidia by better supporting asynchronous shaders on its latest Radeon hardware. As applied to consumer graphics, asynchronous means the ability to run two different workloads on the GPU concurrently. Think of this as rendering graphics and some form of compute, say physics, at the same time. Maxwell GPUs could do this efficiently, but only if the compute and graphics workloads were equal in time length. If not, as is often the case, the GPU would then sit idle while the longest-running component completed.
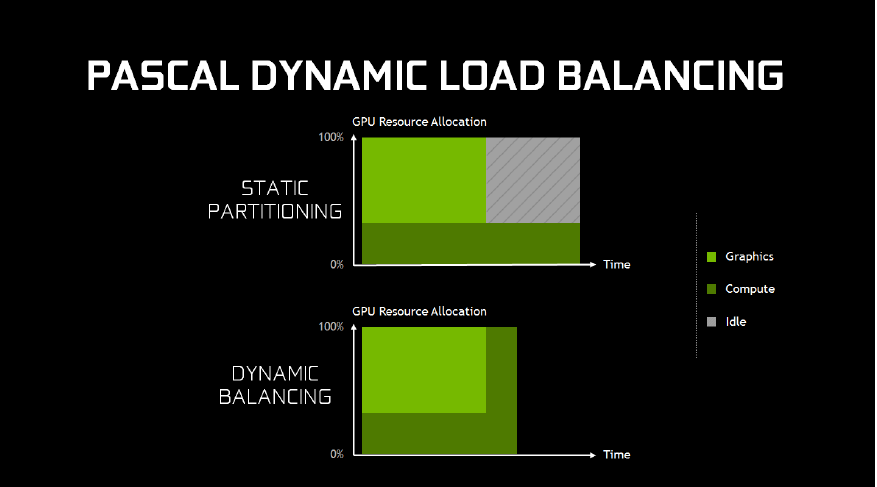
Pascal introduces dynamic balancing where the GPU can be fully utilised when running either type of workload. Note the longer compute aspect is rolled into the spare 'time space' available by having the graphics complete quickly. The net result is less time spent in executing concurrent workloads of different types, which is important if both have to be done before the next set of operations can be undertaken. AMD, it is understood, is said to use some form of similar heavy hyperthreading as present on dynamic balancing.
Knowing What's Coming
Arguably more important than dynamic load balancing is asynchronous preemption. The ideal is that time-sensitive workloads are executed as soon as possible, ensuring that no frames are dropped, but to do this the current workload, in flight, has to be shut off quickly to make way. Most GPUs waste a little time closing off the current workload before being able to switch to the newer, more time-sensitive one. Pascal, it turns out, has what is known as pixel-level preemption (PLP) for graphics.
PLP is a much more fine-grained method of keeping track of the current workload. Should another workload be requested, one if not completed on time would cause rendering issues, Pascal's preemption stops the current workload processing in its tracks, saves what the GPU was doing, and then switches out to the new workload in under 100 microseconds. Once done, the older workload is picked up again from its saved state. Compute preemption is bunched into threads, rather than pixels, yet Pascal works on it the same way.

Why do you care how quickly a GPU can jump in and out of workloads? It's particularly relevant in VR, where you want the asynchronous time warp (ATW) to be as late as possible. ATW is a method by which the VR display relies on the GPU and, to some extent, the CPU's preemption abilities to accurately refresh the display with head movement being considered. Without ATW in place, any movement after the GPU has drawn the scene, but not yet submitted it for display refresh, is not taken into account.
Having the ATW as late as possible enables the best possible match between head movement and what's actually displayed. Nvidia says Pascal's improved pixel-level and thread-level preemption enables the ATW to be sent much closer to the display refresh. Pascal preemption effectively cuts out the wasted time needed in traditional preemption GPUs.
Faster Synchronisation
Here's one for all you gamers who play at sky-high frame rates, and we're talking 100fps-plus here. If your graphics output can easily match the monitor's highest refresh rate then turning V-Sync on results in a smooth experience. The problem is, in some games such as Counter-Strike, the available FPS is much higher than most displays can refresh at. Enabling V-Sync effectively slows the GPU down.
So what if you turn V-Sync off? The GPU runs as fast as possible, spitting out low-latency frames, but tearing can take place as the super-fast GPU, pumping out, say, 220fps, pushes out two incomplete frames that are displayed as one on the monitor, even if it has a 100Hz-plus refresh rate. This is what causes jittering.
Nvidia reckons it has solved this problem for the competitive or eSports gamer who often plays at stratospheric frame rates by decoupling the front- and back-ends of the render pipeline, and this technology is known as Fast Sync.
With Fast Sync active, the front-end of the pipe works as if V-Sync is turned off. It runs as fast as possible with the GPU at maximum warp. Normally these frames would be sent straight to the display if V-Sync was off or tempered to the display's refresh with it on. With V-Sync on, the pipeline uses a couple of buffers, front and back, and the front buffer's frame output is only sent to the display once it is ready to accept at a defined refresh rate. Then the back buffer's contents, which come from the GPU, are flipped into the front buffer which repeats the process.
Fast Sync, however, harnesses a third buffer between frames and display, known as the last rendered buffer (LRB). Its job is to act as an intermediary between the front and back buffers. The LRB has a copy of what's most recently contained in the back buffer and this information is sent directly to the front buffer as soon as it has sent its contents out to display.
The key here is that, unlike a traditional V-Sync on environment, the back buffer is not flipped to the front, nor are additional buffers used for storage. Rather, the latest frames from the LRB, pulled from the back buffer, are sent to the front buffer and displayed as quickly as possible. Point is, Nvidia claims V-Sync on-like smoothness without the speed slowdowns demanded by a fixed monitor refresh rate. It works best on older games used by professional gamers. We'll have to see how well it works in practise.
GPU Boost 3.0
Last but certainly not least, Nvidia introduces the latest iteration of GPU Boost technology which promises more fine-grained control over the GPU's abilities than ever before.
The way in which the GPU jumps up in frequency falls under the auspice of GPU Boost 3.0. Previous GPUs have enabled boost frequencies by pushing the curve upwards across the entire voltage range of the GPU. Though it works well enough, simply shifting the curve upwards means that the frequency potential at other areas of the curve is lost because not all voltage points are considered.
 |
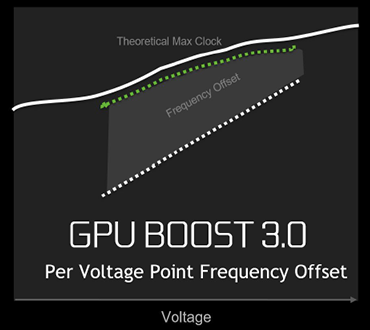 |
GPU frequency scaling is individual to each sample and GPU Boost 3.0 addresses that by now, when overclocking, allowing the user to examine the maximum clock speed for any given voltage point. By looking at the maximum frequency per point, the overclocking curve better resembles the absolute frequency headroom available.
The graphic shows how GPU Boost 2.0 and 3.0 go about their business. GPU Boost 2.0, the left-hand picture, shows how simply forcing the speed up offers extra performance but doesn't maximise the headroom. GPU Boost 3.0, on the other hand, gets closer. The way this is achieved is by letting an overclocking program manually overclock the GPU for each frequency point and then construct the green line on the right. EVGA's Precision X is able to do this though it does take a while to cycle through each point and determine its highest speed.



