





RDNA 2 Architecture, Infinity Cache and Speed

The wait is over. Much has been discussed this year with regard to AMD's fortunes in the high-performance graphics card market. Conspicuous by its absence whilst rival Nvidia has made hay - and lots of cash - with GeForce RTX, today the burden of GPU responsibility falls squarely on much-hyped Big Navi.
Unveiled to gaming enthusiasts as Radeon RX 6000 Series, AMD makes no bones about going toe to toe with the best that Nvidia has to offer. In the red corner, RDNA 2 comes out swinging with next-gen console GPU credentials. In the green corner, Ampere struts its stuff as the current undisputed heavyweight champ. Ding, ding.
RDNA 2
Aiming for a knockout blow, the architecture behind Big Navi is known as RDNA 2. As the name intimates, it builds upon the first-generation RDNA present on the Radeon RX 5000 Series released in July 2019. Bigger and more efficient than its silicon progenitor yet still on ostensibly the same 7nm process, let's explain how AMD got here.
It is important to understand that AMD's aim with RDNA 2 is to improve performance by 2x over the best of the last generation, Radeon RX 5700 XT, whilst also improving performance per watt. The latter is necessary as AMD doesn't automatically gain energy efficiency from the usual process shrink. These are lofty but necessary goals if AMD is to challenge the latest Nvidia Ampere-based graphics hardware where it is strongest.

High-speed Design
Original RDNA is no frequency slouch as partner RX 5700 XT cards routinely boost to 2GHz. Raising the bar this time around, AMD says it has pulled in learnings from its Zen CPU division. As a case in point, considered on a per-CU basis - the building blocks of AMD graphics performance - RDNA 2 can run up to 30 per cent faster at the same power or use half the power at the same speed. Important drivers here are optimised performance libraries, a streamlined microarchitecture, removing frequency bottleneck kinks by looking at the design from top to bottom, and using Zen smarts to extract the last morsel of frequency scaling.
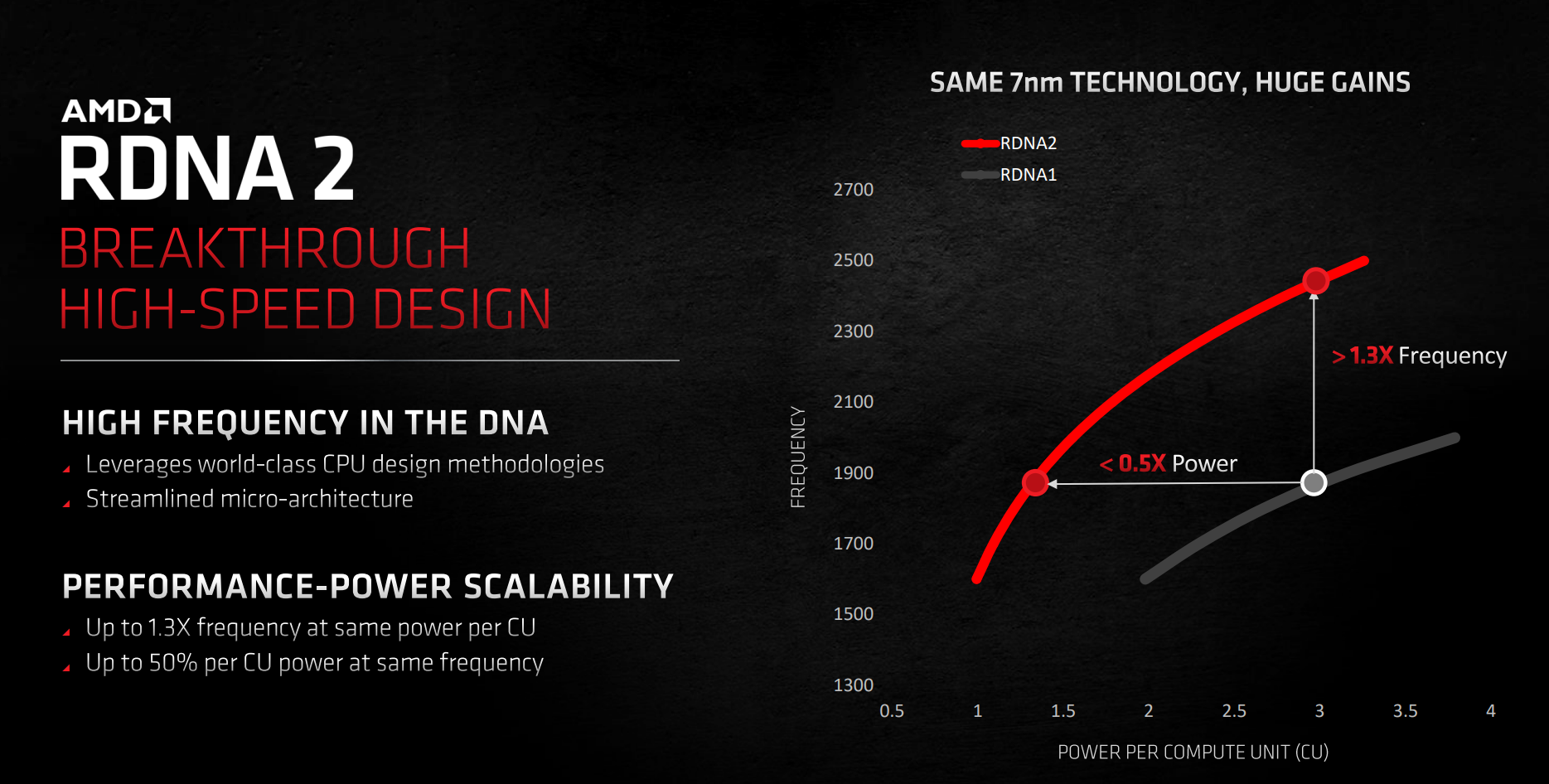
This efficiency and frequency drive is a massive deal in the same process node and it's the fundamental reason as to how RDNA 2 can fit in an 80-CU chip (RX 6900 XT) at 300W, compared with a 40-CU implementation (RX 5700 XT) at 225W for first-generation RDNA.
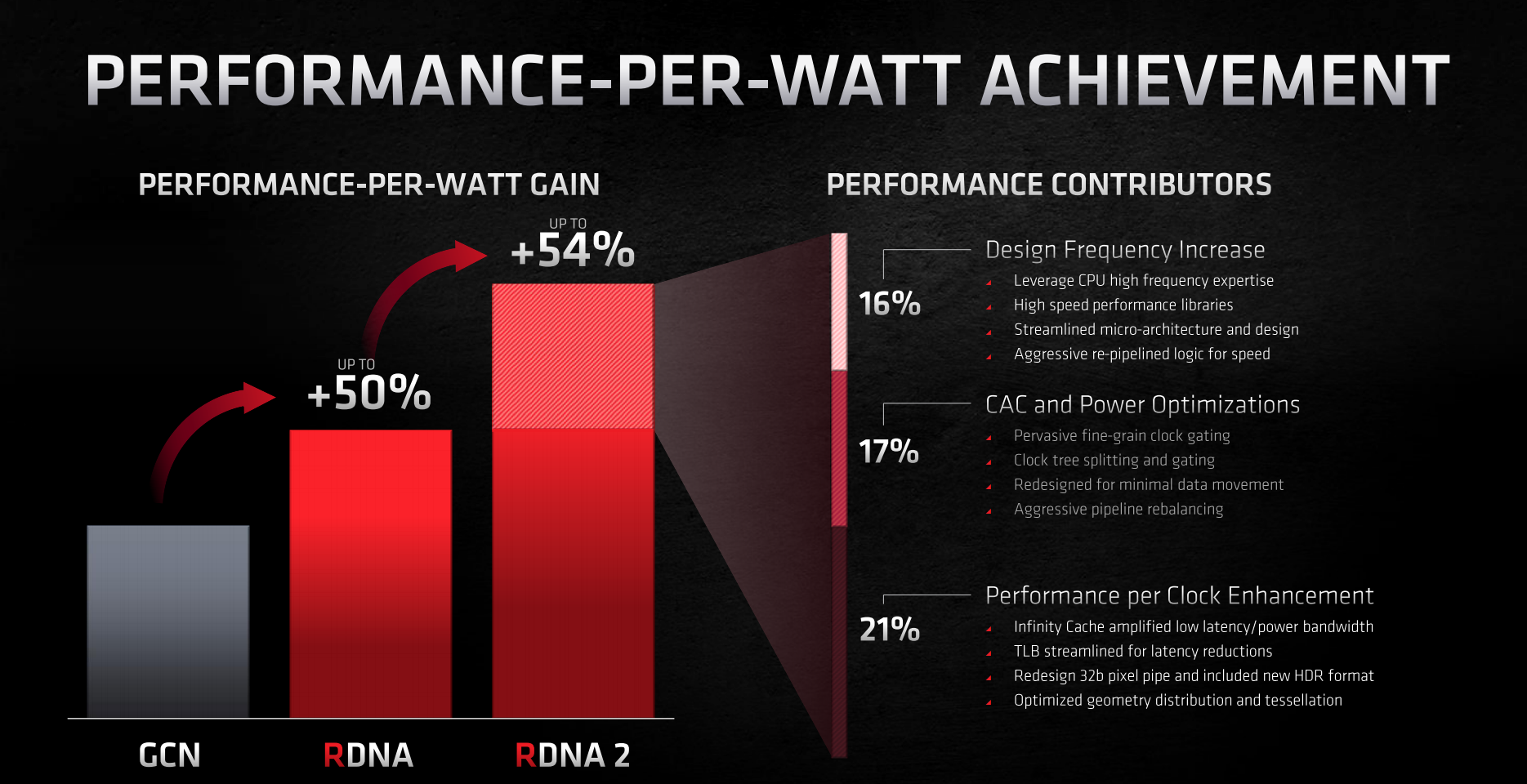
Shoving more numbers your way and describing efficiency in a different manner, RDNA 2 is said to offer up to 54 per cent more performance-per-watt (PPW) over RDNA. AMD breaks down this gain into three further areas: design frequency increase (17pc), power optimisations (17pc) and performance-per-clock enhancements (21pc).
Infinity Cache - Why Now?
Increasing PPW is all about driving down extraneous power usage whilst concurrently lifting IPC. A win-win situation in architecture design. AMD knows that feeding an 80-CU beast effectively requires huge memory bandwidth which naturally burns through power. It would ordinarily be natural for AMD to adopt the latest HBM2 or, say, 384-bit G6 memory operating close to 20Gbps. Both viable solutions inevitably escalate power that immediately damages PPW.
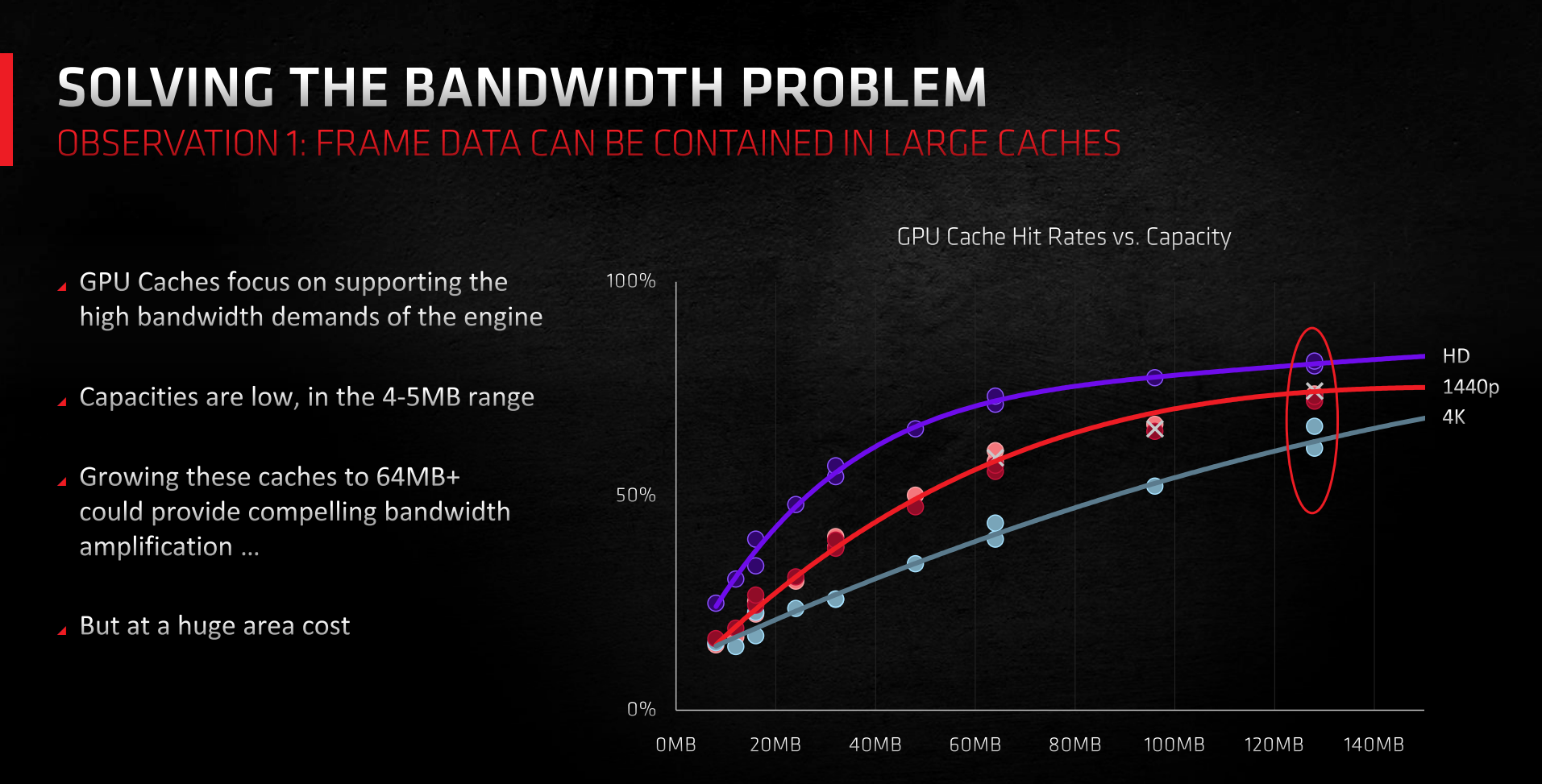
Described as the most significant advance in power efficiency for RDNA 2 and therefore inextricably wrapped up in this PPW drive is a new technology dubbed Infinity Cache. To understand the importance, it's necessary to see how first-run RDNA handles caching. The three-level structure increases in speed the closer it gets to the computational engines, which is the same as CPU design. Makes sense, but by their nature these caches are comparatively small as die area is mostly devoted to parallel-operation CUs and shaders rather than stacks of memory.

Infinity Cache's aim is to replicate the performance goodness of a wider, fatter memory bus but, crucially, without mimicking its power, thus enabling RDNA 2 to hit that all-important PPW metric. AMD said its simulations observed that if a GPU installed a much larger amount of last-level cache on to the chip, then a gaming working set could be mostly contained within it, intimating high cache hit-rates, and thus taking the pressure off the external memory setup. The downside, however, is that a supersized cache would cost a significant amount of die area. There's no such thing as a free silicon lunch.
And by big, we mean big. This cache would need to be at least 100MB to achieve 50 per cent+ hit-rates at a 4K resolution favoured by Big Navi. Handily, it just so happens that AMD's server EPYC CPUs have a high-density, high-bandwidth L3 cache that could be redesigned for GPU duties. Going after PPW means that Infinity Cache is worthy of the die-size investment, and it's present on RX 6800/6800 XT and 6900 XT in a 128MB block. Comprised of cache and connected via Infinity Fabric, it's capable of delivering 64 bytes of data, per clock, across 16 channels, at 1.94GHz.
Crunching the numbers reveals total caching bandwidth of around 2TB/s, or 4x that of a 256-bit external interface to G6 memory. It is reasonable to assume that mid-range RDNA 2 GPUs will have a smaller, slower Infinity Cache, as they're primed for FHD and QHD resolutions.
Running the Infinity Cache provides double the effective bandwidth of a 384-bit G6 bus - necessary for a top-heavy design like Big Navi - at less overall memory subsystem power. Infinity Cache further enables the high-frequency RDNA 2 architecture to better maximise performance at its high frequencies - feeding the beast and all that. Last but not least, having a large on-die pool reduces latency compared to routinely spooling out to G6.
Changing the memory hierarchy on GPUs is a big move. Games engines appear to respond well to the first-run implementation present on Big Navi, and we feel as if this large store of on-chip memory is here to stay on subsequent AMD graphics architectures. How developers tune for it provides an interesting source of technical discussion moving forwards.
If Infinity Cache is such a good idea, why has it not been implemented before? There are myriad reasons, but the most pertinent is that AMD hasn't previously delivered an 80-CU part that needs huge memory bandwidth support. Infinity Cache makes greater sense as the compute engines become more numerous and faster, and respond less well to extreme parallelisation - RDNA 2 fits that bill. It also has orthogonal ramifications for ray tracing, which we'll cover on the next page.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}