





Ampere Exposed
Tensor Thoughts - Half as Many, up to Four Times as Fast
Next up are the Tensor cores, commonly used in Nvidia RTX graphics cards to conduct math matrix operations for features such as DLSS.
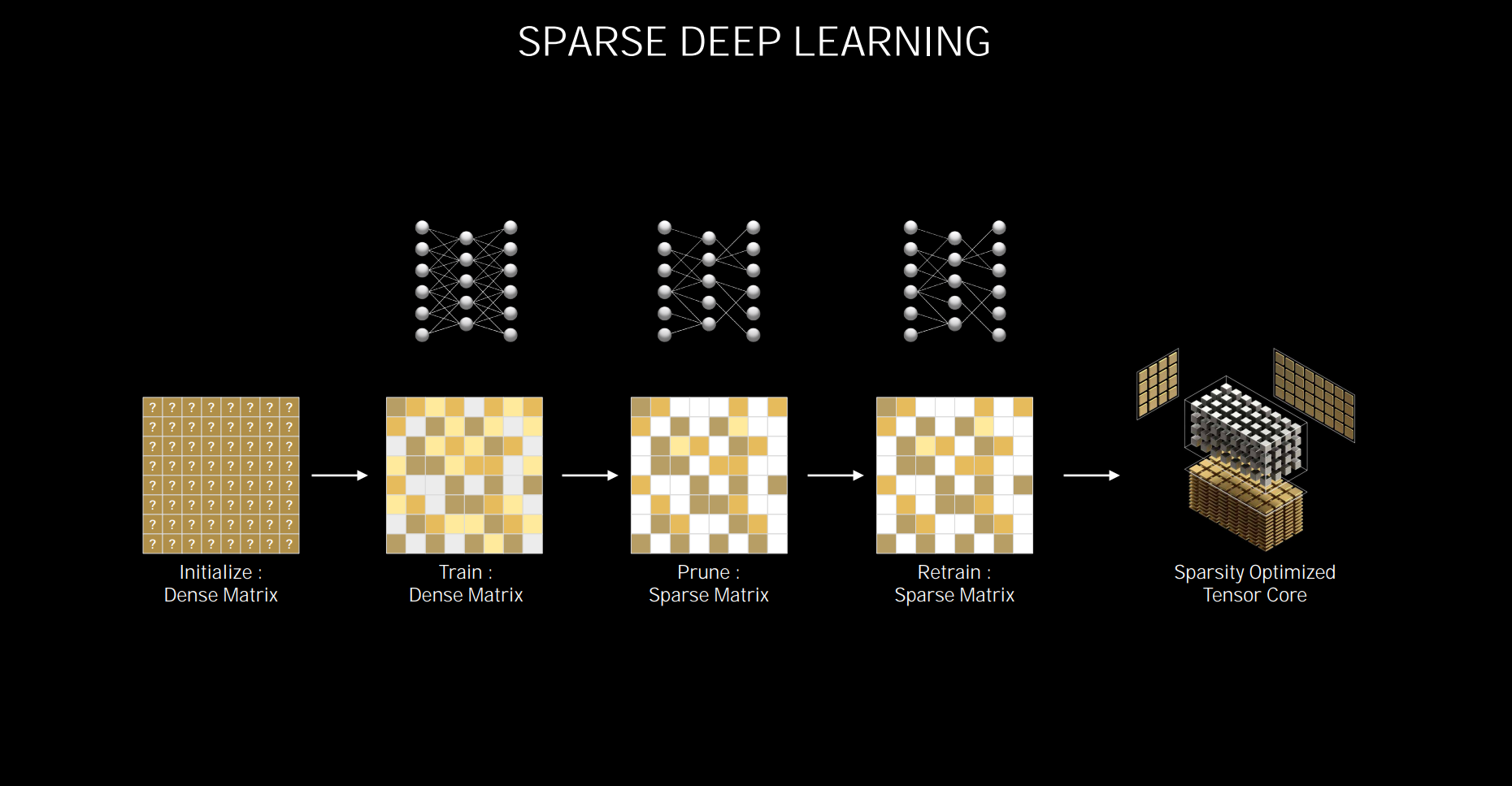
As you will see later on when we discuss the RTX 3080 in more detail, Nvidia has taken the decision to halve the number of Tensor cores per SM, dropping from eight to four. That's not normally a good thing, but something had to give in the SM when doubling up on Cuda-capable cores. Though fewer, each is more powerful, the company says. To realise how, we need to look at the mechanics of deep learning. One originally starts off with what is known as a dense matrix. The training aspect ascribes weights on whether the result is right or wrong, and the higher the weight for a right result. Those deemed the least-important (and wrong) weights are pruned away through a retraining step. What's left is a sparse matrix that's got rid of all the chaff but still retains the accuracy of the dense matrix.

Ampere's benefit is that it can deal with dense and sparse matrices differently. Its cores are twice as fast as Turing's for dense matrix and four times as quick for sparse matrix that have all the needless weights removed. The upshot, per SM, is dense processing at the same speed - it has half the cores, remember - and twice the overall throughput for sparse processing. In a perfect world, you'd want to feed Ampere's Tensor cores with sparsity-optimised matrix all the time. It's fair to say Ampere's Tensor capability is at least as fast as Turing's on an SM basis, but can be quicker depending upon what it's dealing with.
There are also new precision modes such as Bfloat16 and TF32 for greater flexibility when dealing with emerging AI workloads.
Benefits of Truly Concurrent Processing
Remember how Turing can run shading alongside processing on the RT core and Tensor core, helping speed up operations. The left-hand picture below shows the time differential by running workloads on specific cores. The top one is academic as it forces a Turing-based GeForce RTX 2080 Super to run raytracing on the general-purpose Cuda cores. The entire frame takes 51ms equating to an average 19.6fps, which is plainly no good. Having concurrent raytracing processing offloaded to the RT cores reduces time to 19ms, or about 40fps. But then adding the Tensor cores, for in-house DLSS (the purple bit), boosts framerate further, to around 77fps.
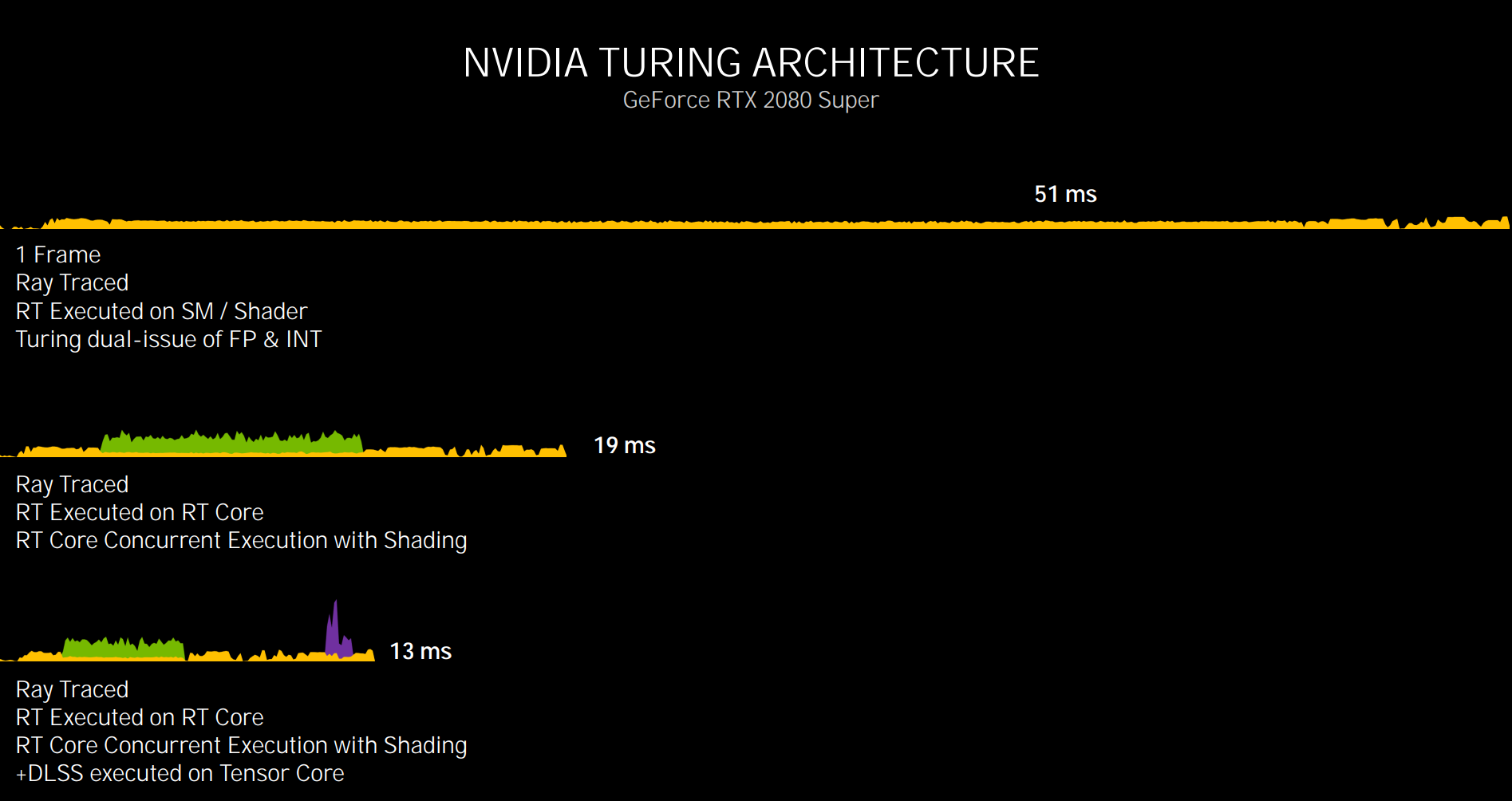 |
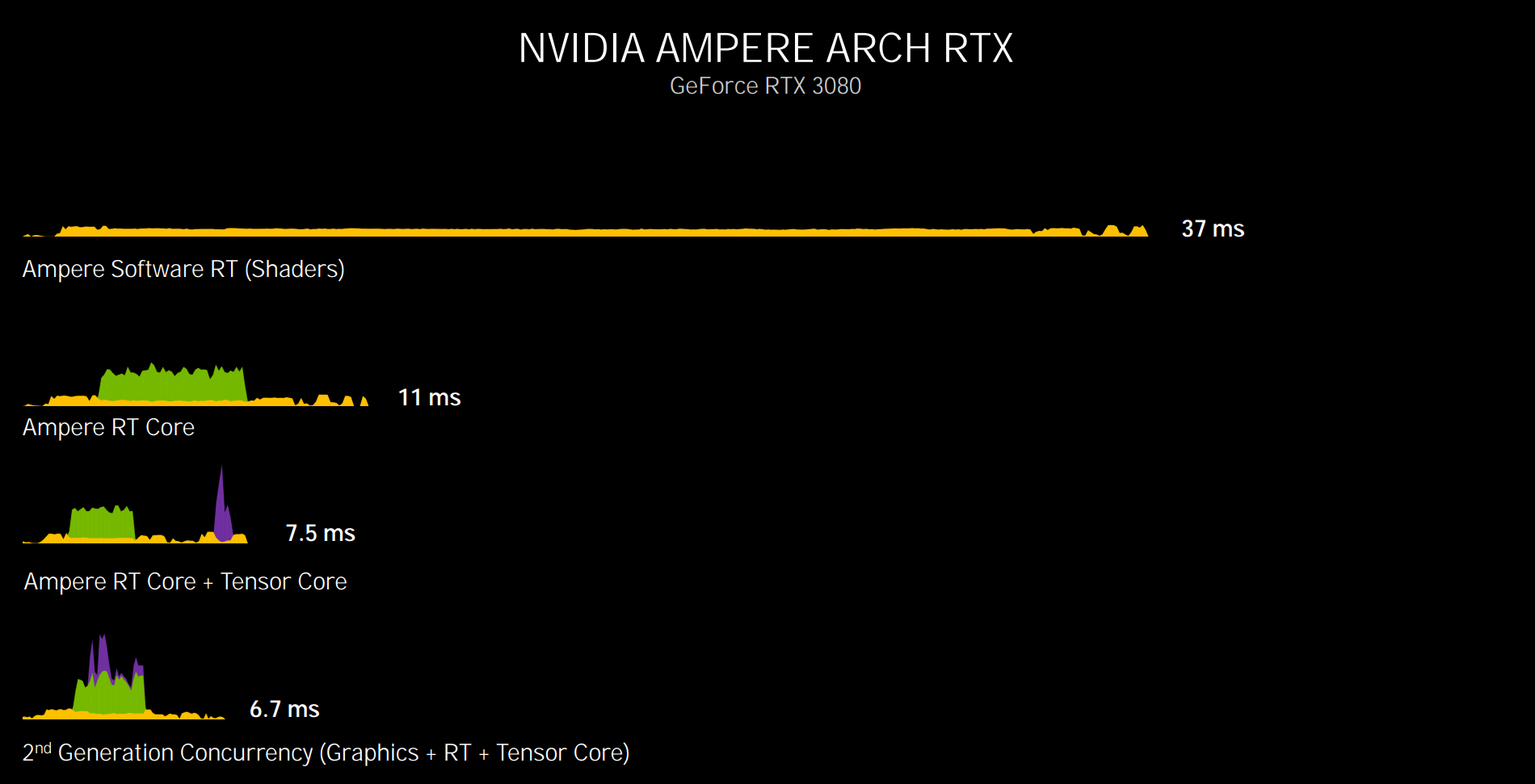 |
On Ampere-based GeForce RTX 3080, which is the natural pricing successor to RTX 2080S, the extra SM horsepower means software-based RT is quicker, at around 27fps. Matching the flow of Turing means Ampere renders exactly the same frame - RT + DLSS - in 7.5ms, or 133fps. Ampere's trick is that it can run all three types or workloads concurrently to shave off a bit more time. Given how one needs to know the result of certain calculations before starting others, this processing may be anachronistic, but it's how, in a roundabout way, when tapping into all types of cores, Nvidia contends the RTX 3080 is twice as fast as an RTX 2080 Super - 13ms vs. 6.7ms.
GDDR6X
All of the improvements thus far are considered front-end optimisations. Having more, efficient cores puts the onus on the backend to keep up. GeForce 20-series' memory interface tops out at 384 bits connected to GDDR6 memory operating at 14Gbps on the RTX Titan. Meanwhile, the RTX 2080 Super runs faster memory (15.5Gbps) albeit at a reduced 256 bits.
Point is, 15.5Gbps memory isn't going to cut it for Ampere-based cards, and going with leading-edge HBM(2) memory is too expensive for consumer cards. Nvidia has therefore worked with Micron to develop GDDR6X memory that offers even higher speeds.
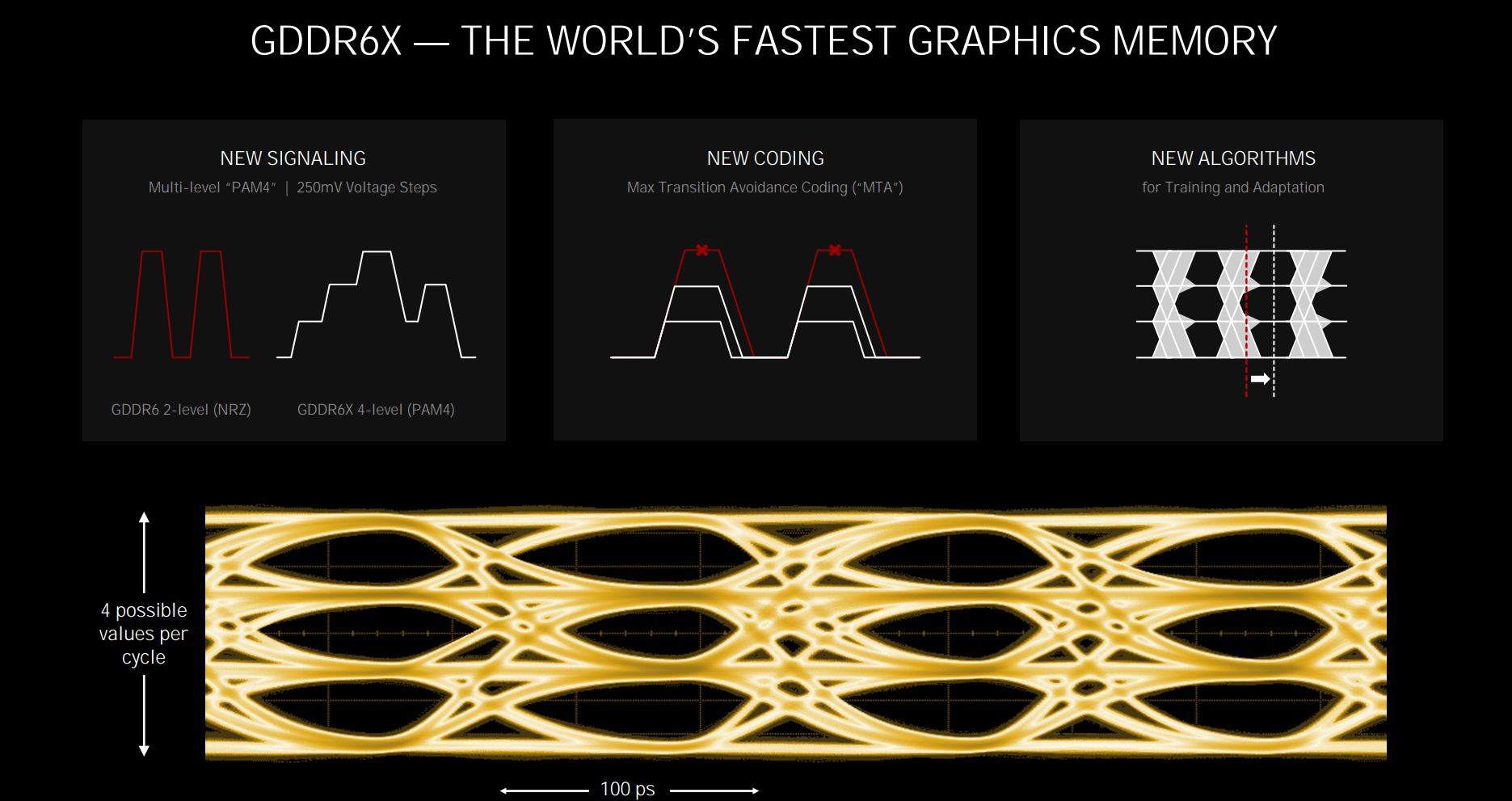
Put simply, GDDR6X doubles the I/O rate of incumbent GDDR6. In particular, the PAM4 multilevel signaling technique sends four voltage levels per cycle, instead of just two (ones and zeroes) for GDDR6. That means double the data per cycle, or the same amount at half the frequency. The innate problem with having more voltage values is the speed at which you can move from, say, one to four, represented by the vertically-stacked 'eyes' on the above picture. It's this transition speed that limits overall frequency.
Nvidia/Micron gets around these max-transition jumps by coding the data - just as it is the networking space - to limit the transitions from one step to the next. By eliminating data being run in a voltage sawtooth pattern, which could happen without coding, GDDR6X is able to run at near-20Gbps straight off the bat. In its finest form, cards based on Ampere offer 384 bits at 19.5Gbps, or a whopping 936GB/s.
Power Musings - Taking it to 320
GeForce RTX 20-series cards hit their performance limit at around 250W through a combination of board design, acoustics, temperature and capabilities of the silicon. Increasing it to, say, 300W resulted in more of the bad and not much extra framerate, as evidenced by overclocked 2080 Ti cards.
Ampere, on the other hand, is naturally quicker due to the performance characteristics discussed in detail above, but continues to scale performance at higher wattages. Speaking to the 320W applied to the RTX 3080, Nvidia says the combination of 8nm silicon and better card designs - we'll get on to the Founders Edition soon - means it keeps on running and scaling. Part of this is down to splitting the core and memory power rails off into independent states. Need to run a Cuda workload that's mostly memory agnostic? Ampere can dial down the GDDR6X voltage and give more to the cores, and vice versa.
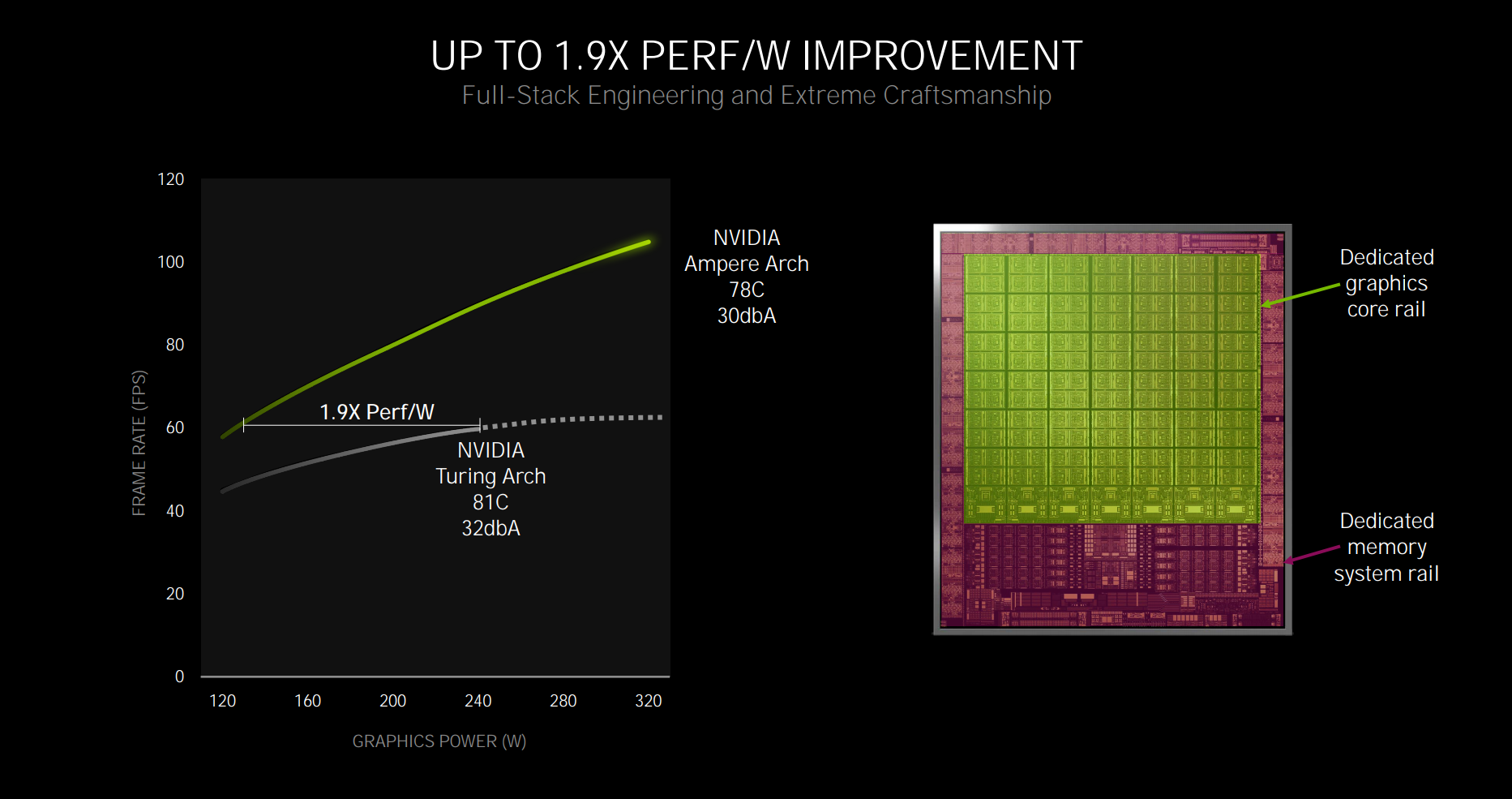
Nvidia is being somewhat clever here. It's promising more performance from Ampere, up to twice as much, but is needing a fair bit more power to do so, to the tune of 28 per cent - 320W vs. 250W - when looking at RTX 3080 vs RTX 2080 Super. We'll talk more about power and perf-per-watt in due course, but it's important to remember that Ampere, hewn from a smaller, more efficient process, needs considerably more juice to function at its best.
Outside of the core blocks, Nvidia adds support for PCIe 4.0, and HDMI 2.1 for 4K120 or 8K60 from a single cable. There's also full hardware decode for the royalty-free AOMedia Video 1 (AV1) codec.
As a summary before we get into RTX 3080, Ampere doubles the number of Cuda-capable cores within an SM, removes bottlenecks on Turing's RT cores, optimises the Tensor cores to run sparse matrices at twice the per-SM speed, cranks up the memory frequency by dint of GDDR6X, and pushes the performance envelope further by scaling to higher wattages.




{kind=link}