





Tensor Cores - An Exciting Opportunity
It's straightforward to see that Turing is more powerful than Pascal. That much is a given when one understands the time between architectures. Having more-efficient SMs, a smarter cache hierarchy and improved memory performance are the trio of improvements we expect to see across generations. Nvidia could have left it there and called these Turing cards the GeForce GTX 11-series, and they'd be a natural performance step up for today's games.
However, in a somewhat unexpected move for gaming cards, Nvidia has adopted more of the professional Volta architecture than many suspected. We know this because each of Turing's SMs is home to Tensor cores, and you see them to the right of the traditional FP32 units in each partition.

Each sub-group/partition carries two mixed-precision Tensor cores, so each SM has eight and there are 576 present on the full-fat TU102 die. That's the same ratio as on the Volta microarchitecture, but Turing improves upon it by offering more modes - INT8 and INT4, for example.
Why would you want Tensor cores on a consumer graphics card and what benefit do they convey over older architectures, notably Pascal? Both good questions. Tensor cores are ideally suited for doing the specialised grunt work behind training neural networks, which is a constituent part of deep learning.
This specialised grunt work is actually not much more than super-intensive general matrix-matrix multiplication operations, commonly known as GEMM. As neural networks become denser and more complicated, general-purpose calculators are simply not fast enough.

To understand why this is, we need to know how the Pascal and Turing architectures handle matrices. Taking a 4x4 matrix multiply and accumulate, Tensor cores multiply that 4x4 grid of FP16 input data (dark green) by another array of FP16 (purple) and then accumulate using FP32 (light green) for what is known as a 4x4x4 matrix-multiply.
Pascal, on the other hand, isn't much slower if running calculations on just FP16 (around half the speed) but really suffers when dealing with the necessary mixed-precision matrices common in computing neural networks. With its specialised cores that excel in this area, Turing is about 8x faster. In particular, each SM's eight Tensor cores perform a total of 512 FP16 multiply and accumulate operations per clock, or 1024 total FP operations per clock
So Turing is far, far better for this type of workload. What use is it for gaming and right here, right now? It's all about the potential benefits deep learning can reap across a swathe of interesting use-case scenarios. Nvidia says the possibilities are almost endless, citing deep learning as being very useful for improving AI in games, generating super-high-res graphics, harnessing a new standard of aliasing known as deep learning super-sampling (DLSS).
Let's take the last one, DLSS, as an example, to show how and why Tensor cores can matter. In normal processing the GPU generates the final frame buffer and then some post-processing takes place to improve that image from a clarity and accuracy point of view. TAA, which is relatively low cost and popular on many games, runs on the shaders and takes the previous frame's data into account and infers where the edges are going to be on the next frame, hence the temporal anti-aliasing name. Most parts of a frame don't change from one to the next, so if you have great motion vectors then TAA ought to work well as it combines frames. Most of the time it does, sometimes it doesn't, and it takes a lot of work from the developer to implement correctly.

Back on point, DLSS, which is an image analysis solution, is well-suited to Tensor-driven AI/deep learning. The way it works is this: Nvidia collects thousands of super-high-res images that are known as 'ground truth' (the best possible, in other words). Nvidia's supercomputers (DGX-1) then run train a network on them so that it can, finally, learn to fill in the missing detail from low-res images and therefore approximate ground truth well. According to Nvidia, 'after many iterations, DLSS learns on its own to produce results that closely approximate the quality of 64xSS, while also learning to avoid the problems with blurring, disocclusion, and transparency that affect classical approaches like TAA.'
Once the network is up to scratch, it is distributed via the cloud to the local Turing card in your PC. It is the job of Turing's Tensor cores to run this distributed network on the images used by the games engine and up the detail accordingly.
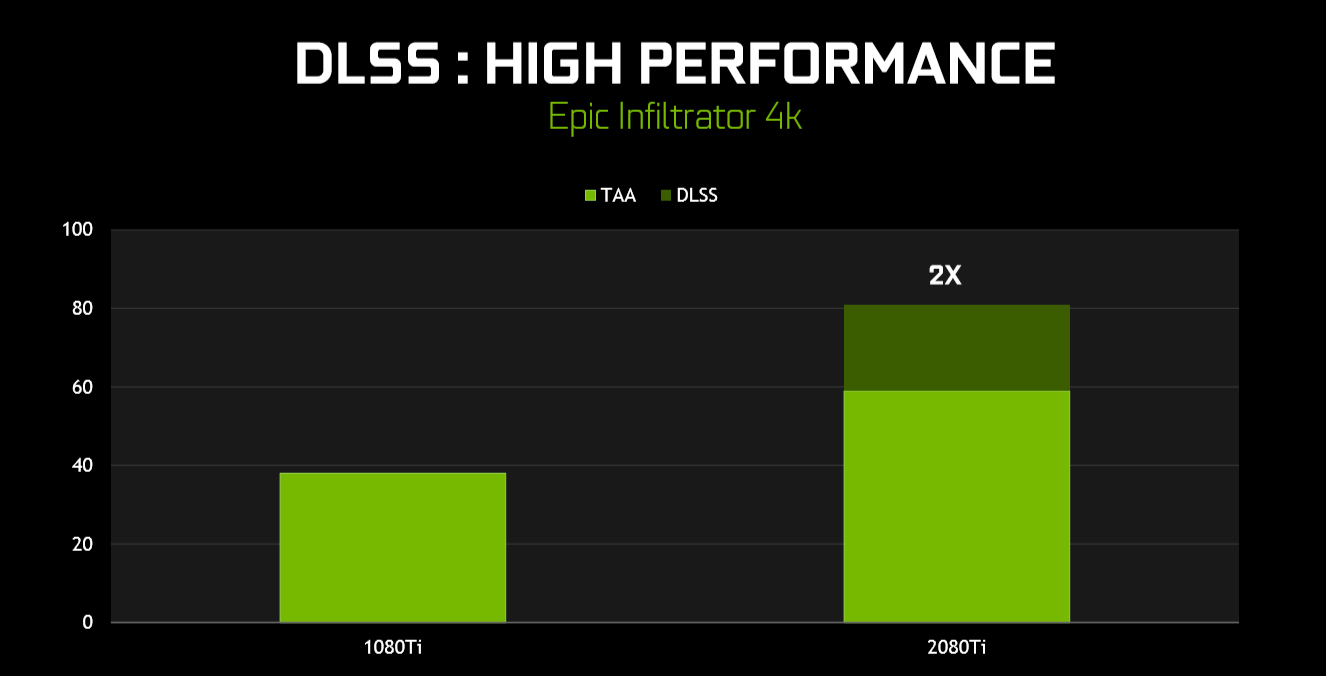
It sounds weird that you can teach a GPU to run a pre-defined network and produce better imagery as a result, but in a demonstration during the RTX event, Nvidia showed that, if implemented correctly, not only does DLSS produce visually better graphics, there's less of a performance penalty for doing so. The reason for this is that the learning network is run on the Tensor cores, not on the shaders. And understanding that it does means it won't be available on pre-Turing architectures.
DLSS support has to be explicit for each game as the ground truth images need to be generated by offline servers, downloaded and the network run via the Tensor cores. So far, 25 games are said to be upcoming, and we look forward to testing it out ourselves.
This is but one example of how deep learning can be applicable to gaming and why Nvidia thinks Tensor cores are necessary in 2018. The proof of the pudding, as they say, is in the eating, because the technology sounds great on paper though widespread real-world implementation is yet to be experienced.




{kind=link}