





Researchers at Google and Stanford University have announced an advanced image recognition software development that is capable of describing and captioning complex photos with far greater accuracy than ever before, reports the BBC.
Most currently available image recognition software is limited to recognising individual objects. However algorithms written by the Google/Stanford team are said to be able to describe photos with near-human levels of understanding, automatically producing captions that identifies entire scenes with a very high degree of accuracy. For example descriptions such as "a group of young people playing a game of frisbee" or "a herd of elephants marching on a grassy plain," were accurately generated by the software.
The research could "eventually help visually impaired people understand pictures, provide alternate text for images in parts of the world where mobile connections are slow, and make it easier for everyone to search on Google for images," explained Google in a blog post.
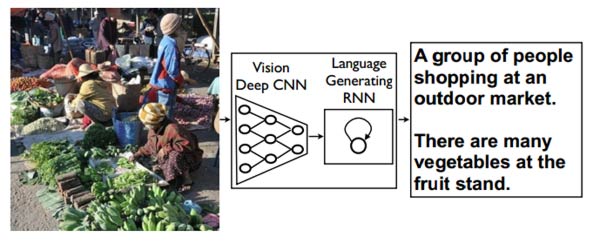
The system uses two neural networks: one which deals with image recognition, and another with natural language processing capabilities. It is capable of learning and can gradually be trained to identify how sentences relate to what the image shows, and as a result, making the captions produced around twice as precise as any previous software could.
As you might expect, the newly developed system is still not perfect, and as you can see from the examples below, it can still get things wrong. Nevertheless, the resulting software makes a huge leap in this AI field, and by training computers to mimic how the human brain works, the research could be beneficial to future breakthroughs in imagery and perhaps even speech identifying software.

"A picture may be worth a thousand words," Google wrote. "But sometimes it's the words that are the most useful - so it's important we figure out ways to translate from images to words automatically and accurately."
Interested? You can find more further details about this project in this paper.







