





HEXUS has reported several times on the progress of artificial intelligence in gaming. The intelligence of AI and computer controlled characters in games can have a big impact on how they play. Furthermore, it is interesting to note the progress as 'machines' learn to outplay their human overlords in a variety of games ranging from the ancient boardgame of Go, to popular eSports titles such as StarCraft.
DeepMind has recently shared some new research concentrating on AI learning and performance in Quake III Arena Capture the Flag (CTF). It has leveraged new developments in reinforcement learning and says its video gaming agents "have achieved human-level performance," in this iconic video games title. Actually, looking at the results graph, it looks like selected AI agents can easily beat humans.
To train its AI agents in this 3D first-person multiplayer video game DeepMind tuned down the graphics to rather basic 'blocky' forms - AI's don't need eye candy. Agents were given no game play rules or instructions, just the goal, and were simply pitted against each other to work out strategies to win. Note that DeepMind reduced the innate super-fast reaction times and trigger accuracy of the agents to be more 'human' like.
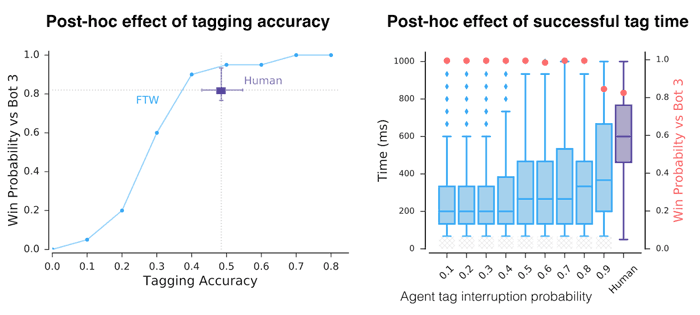
The effect of artificially reducing the agent's tagging accuracy and tagging reaction time after training.
Even with human-comparable accuracy and reaction time the performance of our agents is higher than that of humans.
In CTF the dynamics are complex but DeepMind used the following three ideas to implement reinforcement learning:
- Rather than training a single agent, we train a population of agents, which learn by playing with each other, providing a diversity of teammates and opponents.
- Each agent in the population learns its own internal reward signal, which allows agents to generate their own internal goals, such as capturing a flag. A two-tier optimisation process optimises agents' internal rewards directly for winning, and uses reinforcement learning on the internal rewards to learn the agents' policies.
- Agents operate at two timescales, fast and slow, which improves their ability to use memory and generate consistent action sequences.
It was observed that agents sometimes adopted typical human behaviours like camping in the opponent's base or following around a team mate. Later these behaviours fall out of favour as the agents "learn to cooperate in a more complementary manner".
From all the trainees, DeepMind kept the best performing AI agents, dubbed the For The Win (FTW) agents, and further trained them. The FTW agents ended up exceeding the win-rate for human players. Interestingly, in a test tournament mixing humans and FTW agent's post-game surveys found that "they were rated more collaborative than human participants".
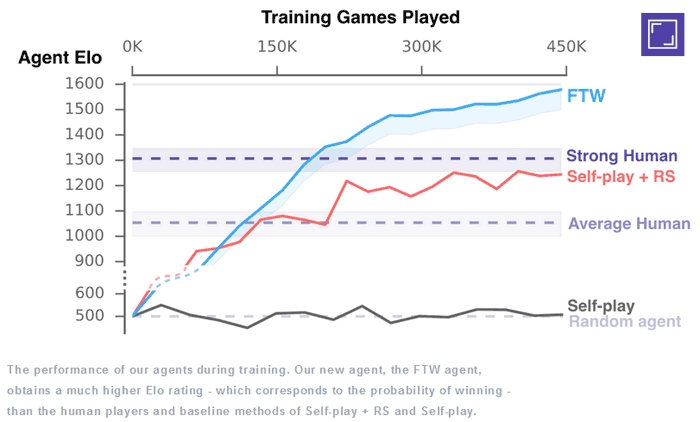
In summary, teaching AI to play Quake isn't frivolous, DeepMind reckons its work "highlights the potential of multi-agent training to advance the development of artificial intelligence," and it doesn't take a lot of imagination to see the potential applications in the real world. You can read more about this DeepMind research on the company blog or in the research paper.







