





Architecture, Implementation
Epyc is based on the Zen architecture that is also the foundation for the Ryzen desktop CPUs. As you may know, those parts top out eight cores and 16 threads, with the assumed, upcoming Threadripper CPU doubling that count, though given the socket change, server-optimised Epyc and client Ryzen 7/5/3 chips will not be interoperable. AMD has since confirmed that, from a motherboard perspective, Threadripper and Epyc are also incompatible.
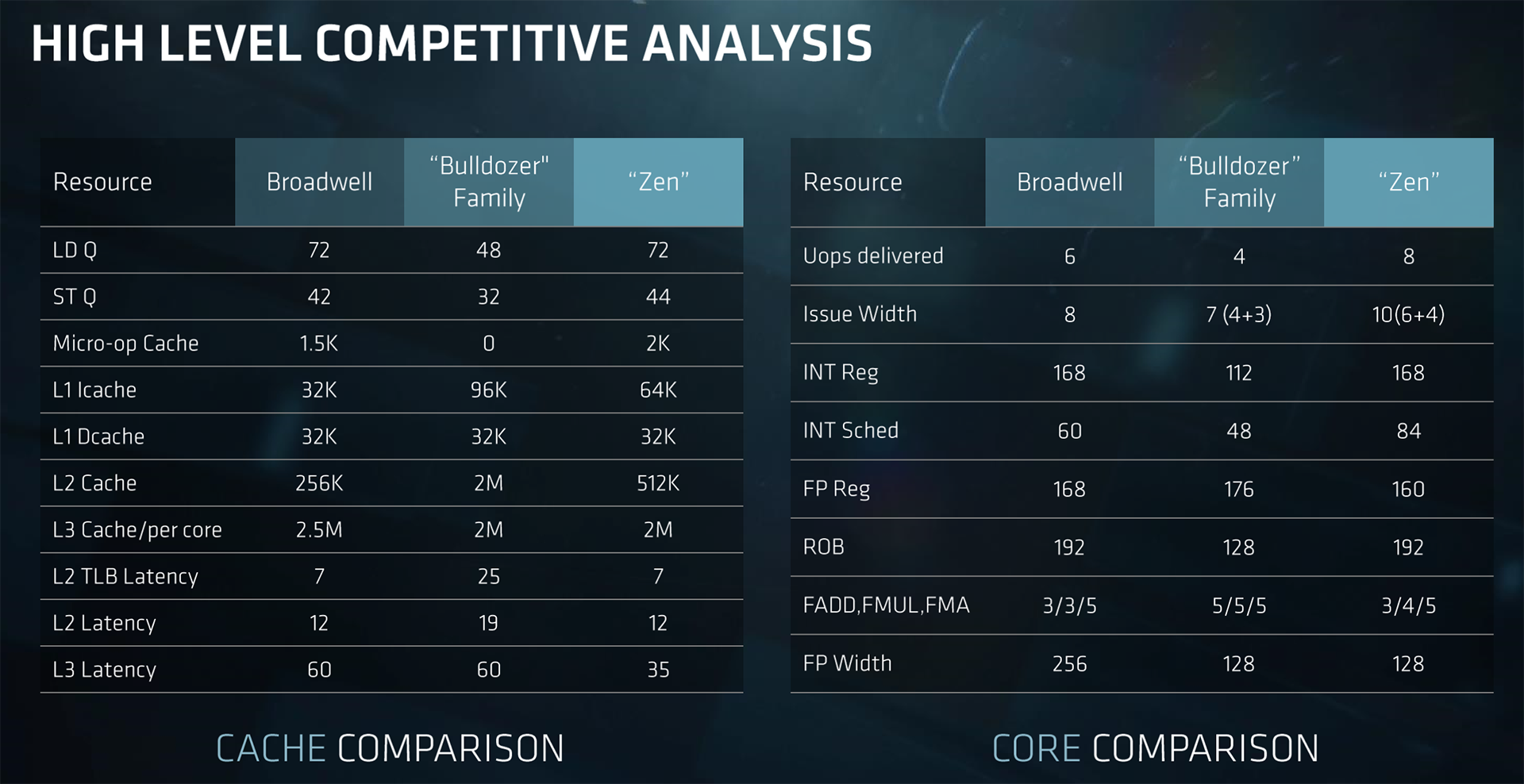
That isn't to say they don't have significant commonality. The core building blocks behind Epyc use the same Zen core as Ryzen, so it's worth refreshing your knowledge by heading over to our introductory article right over here. And if you want a simpler eye chart to see how the Zen core compares with previous Bulldozer and Intel's Broadwell, feast your peepers on this slide.
What's ostensibly different is how Epyc is distinct from an implementation point of view, especially as the core count scales up to 32 in the premier parts. Let's go from the outside in and start with IO first.
Lots of IO

Every Epyc processor possesses 128 lanes of IO, compared with 40 lanes for the latest Broadwell-based Xeons. This means that one can drive a huge number of eclectic devices from a single chip. For example, 64 lanes can be used for, say, four full-bandwidth graphics accelerators, you can chuck another 32-odd lanes for premium storage options, and so on.
Intel's current generation cannot touch this amount of IO, clearly, but AMD's advantage isn't as huge as the base numbers would suggest, as a number of lanes would be reserved for base connectivity such as networking, Sata, etc. Intel encounters the same problem but gets around it by adding 20 or so lanes from its PCH 'southbridge'. The end result, still, is that Epyc enjoys a real-world 2x IO advantage in a 1P environment. That advantage means that fewer on-motherboard switches need to be used to expand lane counts, thus simplifying motherboard design and potentially lowering cost.

These IO lanes can be used for either PCIe (8Gbps), Sata (6Gbps), or grouped together for Infinity Fabric as a chip-to-chip interconnect in a 2P system. In that case, each processor reserves the equivalent of 64 PCIe lanes to connected to one another (128 in total, therefore), hence reducing the potential amount of IO from 256 to the same 128 lanes, as shown in the above picture.
Having heaps of IO being fed in and out of the processor inevitably puts strains on intra-chip and memory bandwidth, so a balanced design needs lots of both to ensure that IO doesn't become a bottleneck.
Moving into the chip - the need for four dies for all Epyc CPUs
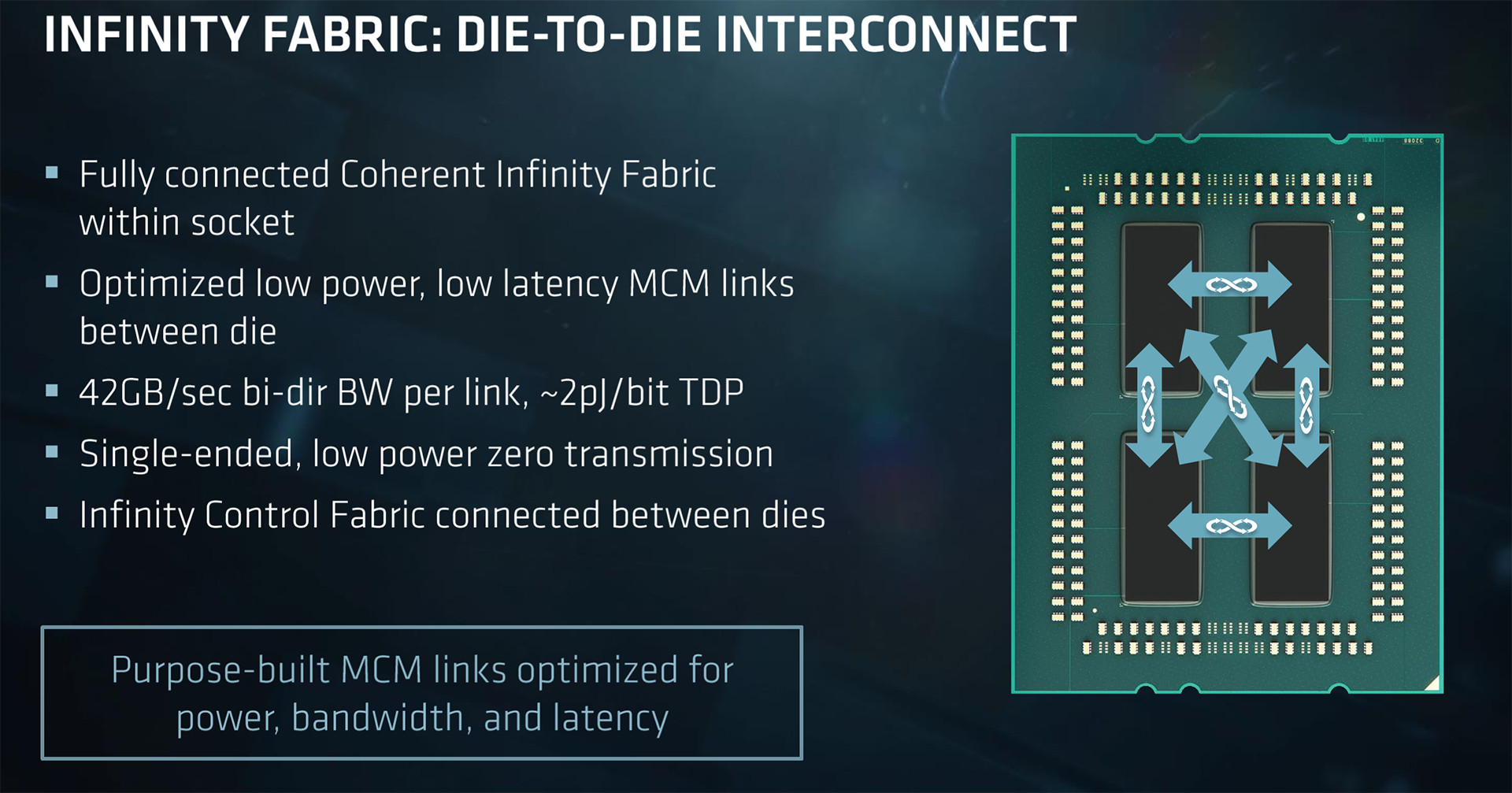
Here is a simplistic view of an Epyc chip, comprised of four dies in a multi-chip module. It is important to understand that all Epyc chips, regardless of the number of stated cores, are built this way.
Making it easy to understand, each of the four dies holds the equivalent of a Ryzen 7 processor. This means two CCX units - each holding four cores and an associated L3 cache - are connected to one another via intra-chip Infinity Fabric. Each two-CCX die has its own, individual dual-channel memory controllers. Adding all this up means that a fully-populated Epyc chip has eight CCXes, 32 cores, and an aggregate of eight-channel memory run at a maximum of DDR4-2666 with one Dimm per channel and DDR4-2400 with two Dimms per channel.
As memory bandwidth is key to solid performance in the datacentre and only two channels are connected to each die, the eight- and 16-core Epyc chips have to use all four dies. Reinforcing what we said above, this also means that all Epyc chips share the same silicon topology - there is no way to get the required level of bandwidth in an MCM setup than by going down this road.
As well as intra-die CCXes connected via Infinity Fabric, each die in turn is also connected to every other one via that Infinity Fabric, operating at 42GB/s bi-directionally, adding up to 170.4GB across four dies. Remember that number.
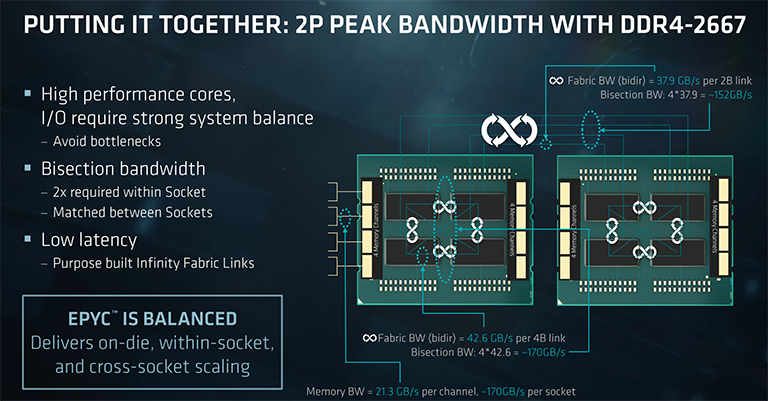
Now let's see if Epyc is a balanced MCM design by looking at effective memory bandwidth and also IO speed.
There's a total 170.4GB/s of aggregated memory bandwidth, too, as each of the eight channels, operating at a peak 2,666MT/s, can shift this amount into the chip. Note that this is for all dies going full chat, as technically each one only has access to two memory channels.
Looking at a 2P system, the inter-chip Infinity Fabric offers up a potential 152GB/s between processors, intimating that all the theoretical numbers stack up, that is, show no obvious signs of bottlenecking.
There may be some traffic IO-to-memory bottlenecks in a 1P environment where almost all of the 128 PCIe 3.0 runs are used for super-fast storage; each die has 64GB/s of PCIe bandwidth and, as we have seen, 'only' 42.6GB/s of memory transfers available.
Point is, building an efficient MCM chip with lots of IO hanging off it also requires tonnes of memory bandwidth and lots of intra- and inter-die bandwidth, as well inter-chip speed. Epyc would not have been possible without Infinity Fabric there to hook it all up.




{kind=link}