





Architecture musings II
What about texturing?
Unlike G80 where texturing units are strapped on to a bunch of stream processors, the Radeon HD 2900 XT has four distinct texture units that supply all the SPs. Each texture addressing unit carries eight texture-address processors, four for bilinear filtering and the other four for the many types of unfiltered. Looking closer, R600 has a total of 16 FP32 texture filter units for ultimate precision (128-bit) and good looks (and part of DX10 spec) with filtering at half speed (8ppc), or two cycles. FP16 filtering is run at full speed, that is, 16ppc.HD 2900 XT has the expected L1 texture cache (32KB, 4x larger than R5xx) and a larger vertex cache (32KB) to, again, keep the R600 packed with available data to be processed. The more data you can push through and the greater the internal amplification, the greater the opportunity for polygon throughput - and higher numbers are better for any graphics card.
Further, keeping it all humming along without too many stalls, it packs in a 256kB L2 texture cache. It goes without saying that the GPU's texturing capability is open to all the various shaders, but I'll say it anyway. Summary: good-looking pixels at high speeds. Talking about filtering, AMD is now using high-quality anisotropic filtering as default in the R600's control panel.
ROPs
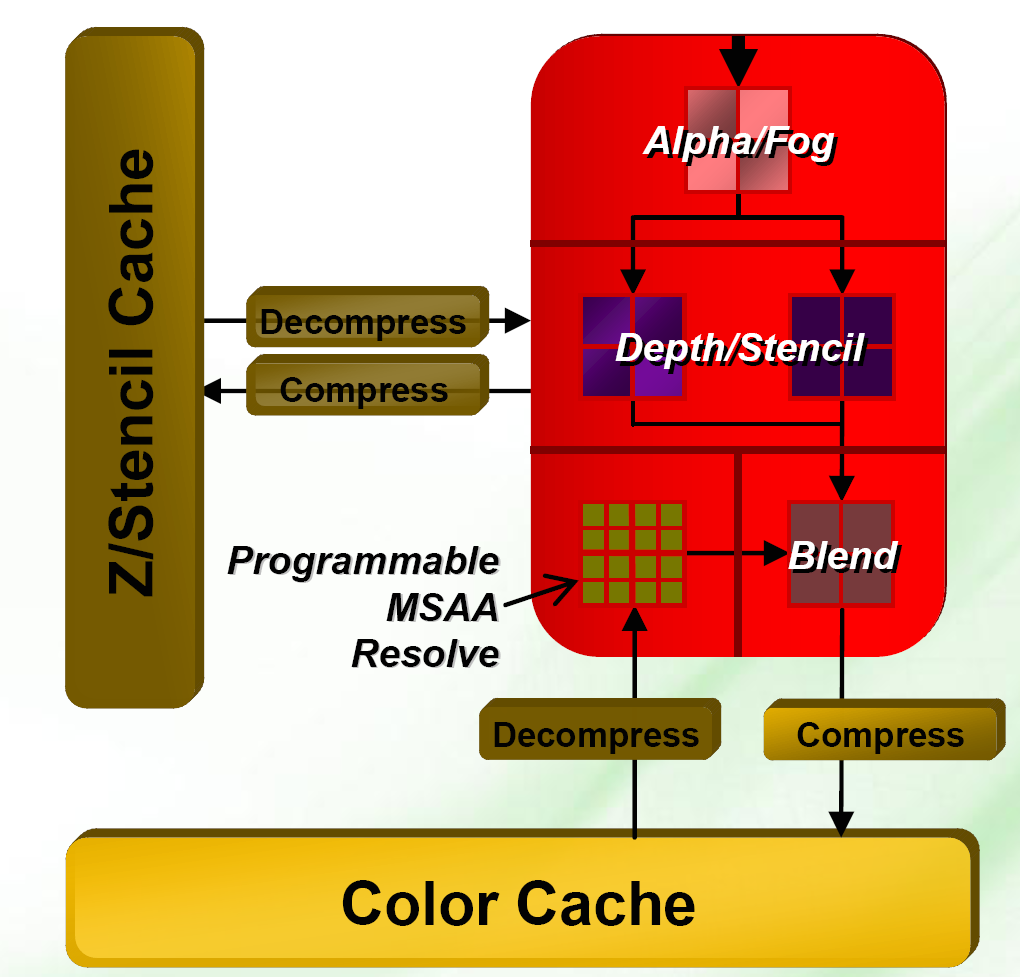
Every GPU needs 'em. ROPs is where you go once your stream-processors have done their job and now what's required is accurate rendering of what's been produced above. The 16 ROPs knock out 16 pixels per clock cycle and can deal with 32 depth/stencil samples - and with better Z-buffer compression than before. Unlike the R500, compression data is now not on-chip; it's virtualised (system or addressable memory) and loaded when needed. Performance, then, should be better at ultra-high resolutions, and we'll test that.
ROPs are also important because it's here that real quality is taken care of - antialiasing is applied and the HD 2900 XT has some funky implementations. The Radeon HD 2900 XT, and indeed the entire 2K series, uses what's known as a programmable MSAA resolve (Custom Filter), which takes in all the samples generated by upscaling and then determines what the final on-screen pixel will look like, but changes the method by which that final pixel is arrived at. Custom Filter AA, upgradeable via software patches, introduces various new filter modes that add in more samples where they're needed most. We suppose it's an enhancement that mixes and matches various filters for user-generated image quality. Rys at Beyond3D examines just how good it is in relation to NVIDIA's contender.
The ROPS are ultimately connected to a revised ringbus controller. Radeon HD 2900 XT ROPs support multiple render targets (MRTs), where the GPU can render fragment shaders into eight multiple outputs (buffers). Handy for developers and GPGPU folks.
By the way, Radeon HD 2900 XT also features what's termed a 'stream out' (R2VB) feature, where the vertex or geometry shader's output can be circumvented from going directly to the ROPs, as is usually the case, and, instead, be sent to system RAM. It's useful in situations where the output is required several times and is similar to the Xbox 360's MemExport feature and also present in the R500-series.
Memory bandwidth and the new ringbus controller
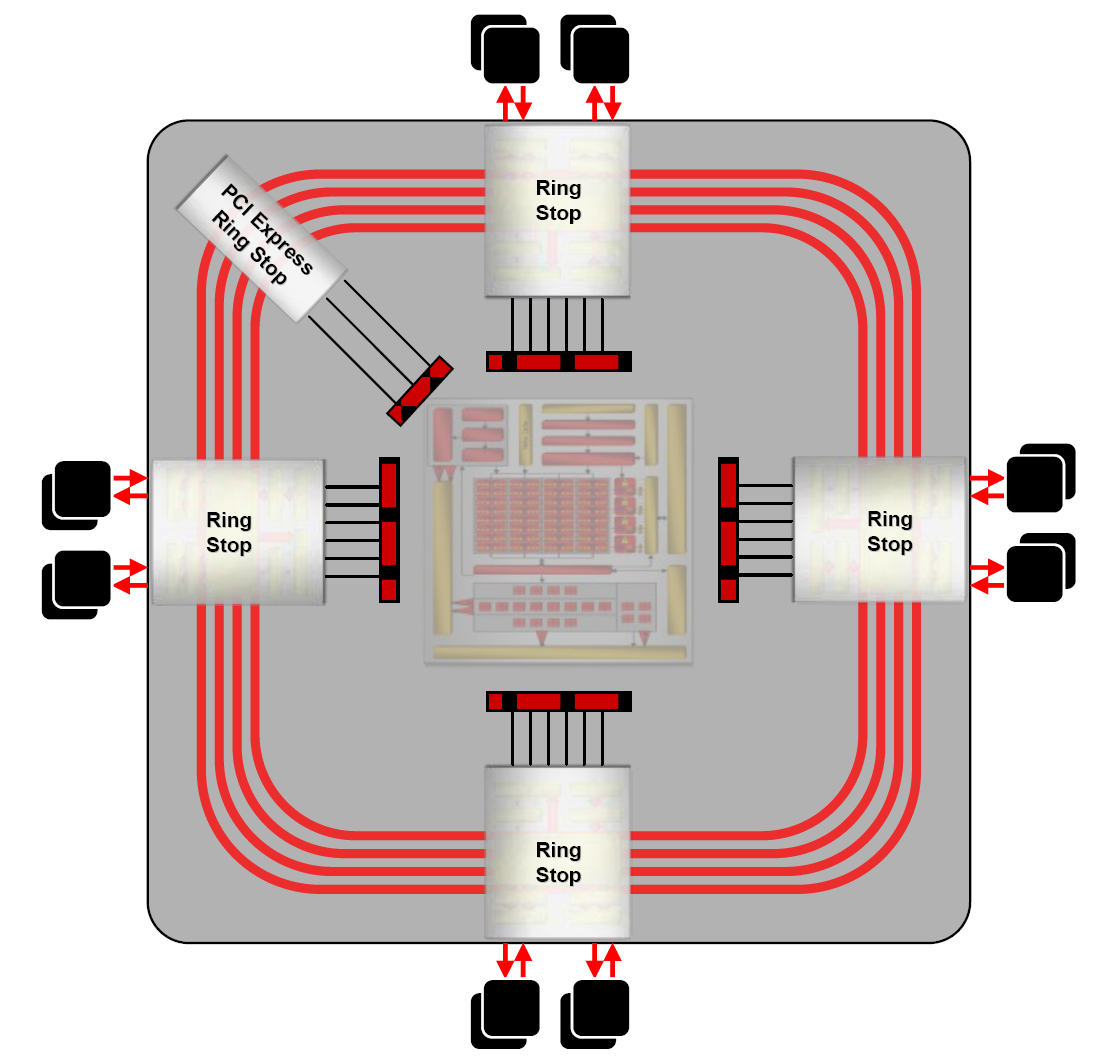
ATI introduced the ringbus memory controller with the X1K series. The new kilobit interface uses two sets of rings, each 512-bit, for reads and writes. This distributed setup links to eight 64-bit memory channels and therefore offers an external 512-bit interface. AMD has been able to accomplish it by using a new pad-stacking process that doubles the I/O density (for the same space) compared to the X1K range.
A doubling of the external memory interface and speedy internal hookups are hugely important for performance at high resolutions with decent image quality. A wider interface also allows AMD to continue using cheaper DDR3 modules and still provide gobs of bandwidth.
CrossFire and Physics
The Radeon HD 2900 series will, of course, provide CrossFire support for multi-GPU operation. AMD's abolished the archaic master/slave system and all GPUs carry the necessary CrossFire compliance. Physics is supported, although the gaming industry requires more physics-accelerated titles for most to consider using an HD 2900 XT for that purpose.Briefest of summaries
AMD has followed the DX10 spec and endowed the R600 with a fully-unified shading architecture that is able to dynamically allocate workloads to the multi-purpose superscalar stream processors via an intelligent ultra-threaded dispatch processor. AMD's introduced caches at the key junctures and raster operators that promise the best visual quality ever.Memory bandwidth - that oh so crucial element for high-performance graphics and cool-looking post-processing - is beefed up via the use of a 512-bit (external) fully-distributed memory ringbus. Oh, and R600 features hardware tessellation that should be easy for developers to program for. Radeon HD 2900 XT also promises to be good at painting high-quality textures and promises improved high-quality anisotropic filtering.
The architecture seems reasonably well-balanced but doesn't feature the split-clock domains as found on G80. The Radeon HD 2900 XT will be clocked in at 742MHz core/shader and 1650MHz (effective) GDDR3 memory. That's 475GigaFLOPs and over 100GB/s of memory bandwidth. It would have been fantastic a year ago but NVIDIA has been able to do pretty much the same thing for six months.
It will be up to the driver team to leverage the best out of a superscalar architecture. It will be interesting to see how performance improves over the next few months.
Stacking it up - the numbers.
| Graphics Cards | ATI Radeon HD 2900 XT 512MiB | AMD Radeon X1950 XTX 512 | NVIDIA GeForce 8800 Ultra 768MiB | NVIDIA GeForce 8800 GTX 768MiB | NVIDIA GeForce 8800 GTS 640 | NVIDIA GeForce 8800 GTS 320 |
|---|---|---|---|---|---|---|
| GPU clock | 742MHz | 648MHz | 612MHz | 575MHz | 500MHz | 500MHz |
| Shader clock | 742MHz | 648MHz | 1500MHz | 1350MHz | 1200MHz | 1200MHz |
| Memory clock (effective) | 1650MHz | 2000MHz | 2160MHz | 1800MHz | 1600MHz | 1600MHz |
| Memory interface, size, and implementation | 512-bit, 512MiB, GDDR3 | 256-bit, 512MiB, GDDR4 | 384-bit, 768MiB, GDDR3 | 320-bit, 640MiB/320MiB, GDDR3 | ||
| Memory Bandwidth | 105.60GB/sec | 64.00GB/sec | 103.68GB/sec | 86.40GB/sec | 64.00GB/sec | |
| Manufacturing process | TSMC, 80nm (80HS) | TSMC, 90nm (90HS) | ||||
| Transistor Count | 700M+ | 384M | 681M | |||
| DirectX Shader Model | 4.0 | 3.0 | 4.0 | |||
| Vertex Shading | 320 FP32 scalar ALUs, MADD (Unified) | 8 vec4 + scalar ALUs, MADD co-issue | 128 FP32 scalar ALUs, MADD+MUL dual-issue (Unified) | 96 FP32 scalar ALUs, MADD+MUL dual-issue (Unified) | ||
| Fragment Shading | 320 FP32 scalar ALUs, MADD (Unified) | 48 vec3 + scalar ALUs, MADD+ADD dual-issue | 128 FP32 scalar ALUs, MADD+MUL dual-issue (Unified) | 96 FP32 scalar ALUs, MADD+MUL dual-issue (Unified) | ||
| Geometry Shading | 320 FP32 scalar ALUs, MADD (Unified) | N/A | 128 FP32 scalar ALUs, MADD+MUL dual-issue (Unified) | 96 FP32 scalar ALUs, MADD+MUL dual-issue (Unified) | ||
| ROPs and AA | 16 Up to 24x CFAA |
16 Up to 6x MSAA |
24 Up to 16x CSAA |
20 Up to 16x CSAA |
||
| Pixel fillrate | 11.872GPixels/s | 10.368GPixels/s | 14.68MGPixels/s | 13.8MPixels/s | 10GPixels/s | |
* - all scalar ALUs are cross-shading, so, for example, AMD Radeon HD 2900 XT has a total of 320 stream processors and NVIDIA's GeForce 8800 Ultra a total of 128.
Unified shading is pervasive here, with all but the Radeon X1950 XTX (DX9) supporting it. AMD's Radeon HD 2900 XT has more stream-processors but NVIDIA's are clocked in at a higher rate and can accomplish more work per unit, so comparing them is not as easy as it might appear at first glance.
Thinking about the architecture and pure numbers in relation to the competition, the Radeon HD 2900 XT may not best the performance of the GeForce 8800 Ultra and 8800 GTX. Initial driver support will be not up to NVIDIA's standards - it's had longer, and a slower shader clock and pixel fillrate will impinge upon performance somewhat.



