|
HyperThreading works by extending the SMP school of thinking to a single processor die. It adds certain duplicate logic and partitions certain CPU resources and shares others in such a way as to create more than one processor from a single physical CPU package.
SMP is the simple implementation of add more workers, get more work done. This is then abstracted down onto a single CPU die.
To create more than one processor from a single underused Netburst die was fairly trivial for Intel in terms of extra die space used. Duplicated logic is kept to a minimum and consists only of the logic needed to save thread state and execute a running thread on the processor. This sort of thing includes logic to save and restore thread context, the instruction pointer (so that the thread knows where to carry on when it gets swapped onto the CPU), register renaming logic (used by the thread when working with data), the return stack predictor (so the CPU can guess intelligently at what data will be on the CPU stack when a thread next executes) and the instruction buffer for the executing thread.
They are the bare minimum sets of logic needed to run a thread on the processor. Then some resources are partitioned per logical processor. Partitioned resources on the processor are mostly buffers like the load/store buffer. Say the buffer has 20 entries, it will be split up equally depending on the number of logical processors.
The remaining resources on the CPU are shared. These are mainly the CPU caches including the 20kb L1 (8kb data, 12kb uOp trace cache) and 512kb L2 caches and out of order execution logic (instructions aren't executed in order, a wasteful practice, instead they are optimised on the CPU so that as many instructions per clock can be executed). The caches are blissfully unaware there may be more than one processor using it, they just load and save data as requested by the other resources on the processor regardless of what thread is manipulating that data. This has 2 sides as far as performance is concerned.
Since the cache isn't split or partitioned, it may happen that more than one logical processor might need to make use of the same area in cache and that causes cache misses and cache thrashing. Say CPU0 wants data from an area on L2 cache and CPU1 needs some data from the same area? One of the CPU's is going to experience a cache miss and stall its part of the pipeline until the data is there in cache ready for it to execute. If this then happens right before a context switch and two new threads are then scheduled on the processors, it can happen again very quickly. With context switches and cache misses being two of the most costly operations on a processor you don't want them happening too much. Obviously that's one of the worst case scenarios, the compiler can help here in keeping good data in the CPU cache that logical processors can make good use of. Cache alignment issues are another performance killer on Netburst, it can take a good few clock cycles to align data to cache boundaries so that it can be read over a cache line.
Those techniques combined serve to create more than one logical processor from a single physical processor die in one physical package. On current HyperThreading implementations on this new 3.06GHz processor the HT logic creates 2 processors on one die and the same is true on HT supporting Pentium 4 Xeons. There is nothing stopping more than two logical processors from being implemented on a single Netburst core, but two seems to optimal at the moment and of course it needs less extra CPU logic and die space than any other implementation.
So when HyperThreading is enabled on a supporting processor by the system BIOS and the dual I/O APIC's are setup and registered, a current HT enabled processor looks like 2 physical processors to the supporting operating system. As far as the operating system is concerned there are 2 processors to work with and it will schedule threads accordingly as outlined on the previous page.
The only thing remaining to touch on before examining performance is processor affinity. Processor affinity on Windows operating systems that support SMP implementations like HT means that you can force applications to only execute on a certain processor. Without affinity, Windows will attempt to schedule the threads equally over all available processor to balance processor load. So a single processor intensive task running on a 2 processor system under Windows without processor affinity set will be run on both processors at the same time with threads from the application dispatched and executed on both processors.
With affinity, the CPU intensive task will be forced to the specified processor. This can be set by the user or specified by the application itself. Lets take a look at a few of the scenarios available using SETI and SETI Driver which can set processor affinity on dual processor systems to force 2 copies of SETI to run on seperate processors or to let the operating system handle the CPU scheduling and dispatch SETI threads to whatever CPU it chooses.
Single SETI instance, no affinity
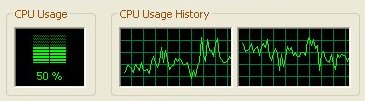 Here you can see WinXP scheduling the single SETI instance over both HT CPU's giving an average of 50% CPU load
Here you can see WinXP scheduling the single SETI instance over both HT CPU's giving an average of 50% CPU load
Dual SETI instance, no affinity
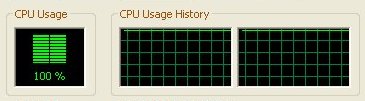 Here you can see both SETI instances running on both availble CPU's but with no affinity set it's impossible to know what CPU is running what SETI instance at any one time.
Here you can see both SETI instances running on both availble CPU's but with no affinity set it's impossible to know what CPU is running what SETI instance at any one time.
Single SETI instance, affinity
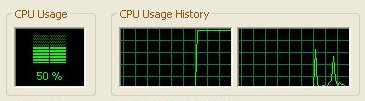 Here you can see WinXP scheduling the single SETI instance on one HT processor with affinity set leaving the other CPU idle
Here you can see WinXP scheduling the single SETI instance on one HT processor with affinity set leaving the other CPU idle
Dual SETI instance, affinity
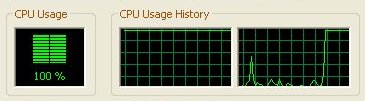 Looking to the right edges of both graphs, you can see the same effect as dual instances with no affinity. We are simply forcing the processors rather than letting WinXP decide, the net result is the same.
Looking to the right edges of both graphs, you can see the same effect as dual instances with no affinity. We are simply forcing the processors rather than letting WinXP decide, the net result is the same.
Since the benchmarks we run at Hexus are not multi processor aware, it's up to Windows to decide what CPU to run our benchmarks on when it schedules their executing threads. The first scenario outlined above is the scenario that occurs during benchmarking. A single instance of the multiprocessor unaware application with no affinity, letting Windows choose the CPU.
Finally, it's worth mentioning that different types of SMT, SMP and CMP can be combined. SMT or symmetric multi threading is the HyperThreading in this case. SMP or symmetric multi processing is the act of having more than one processor in a computer system. HyperThreading is also an SMP implmentation but the traditional implementation is 2 or more seperate physical processor packages that don't implement SMT. CMP is chip multi processing or multiple CPU dies on one physical package. This SMP implementation is used by IBM in their Power4 processor which have 2 distinct physical processors on one package.
They can theoretically be combined. For instance there could be a dual 2 chip CMP implementation (4 distinct physical processors, 2 per package, 2 chip packages implemented) and then have a form of SMT such as HT implemented on each of the 4 processors giving 8 logical processors from 4 physical CPU dies contained in only 2 CPU packages. Confusing? You bet.
|









