





Benchmarks I
I'll start of the benchmark batting with SiSoft SANDRA's synthetic tests. From a benchmarking perspective, their consistency becomes a valuable tool. I'll start off with the synthetic CPU benchmark
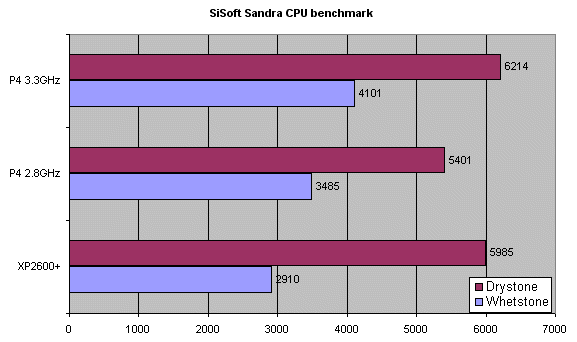
The Athlon wins the non-overclocked Drystone race, but the P4 strikes back with a resounding victory in the Whetstone figures. The 3.3GHz Pentium 4 runs amok.
How about the buffered memory benchmark ?.
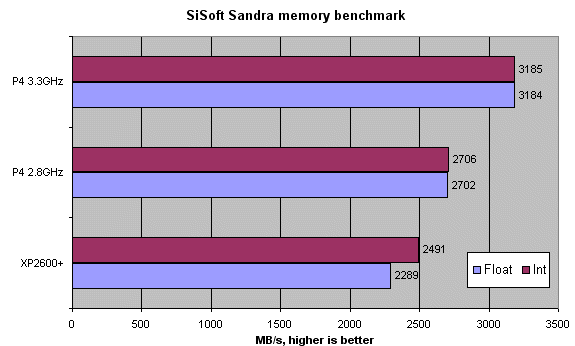
Even though the Athlon XP2600 is accelerated to a 170MHz FSB (12.5*170), and is therefore almost on a parity with the 178MHz memory speed of the 2.8GHz P4 (133FSB with memory at 3:4 ratio), SiSoft SANDRA looks unkindly upon the Socket A platform. The Pentium 4, on the other hand, is shown in an impressive light as it utilises up to 97% of available buffered bandwidth, according to SANDRA.
The P4, when run at 3.3GHz, runs with a memory speed of 210MHz (157FSB, 3:4 ratio). The important fact to remember here is that I had to lower timings to accommodate this increased speed. I used 2-5-2-2 timings at 178MHz memory and 2-6-3-3 timings at 210MHz. The lowering of timings, although not represented fully in SANDRA, will have a negative impact on the upcoming results.
Let's run Pifast and find out if the new P4's increased clock speed can hold off our artificially enhanced XP2600. Pifast simply calculates the constant Pi to a set number of decimal places. A fast FPU and oodles of bandwidth are the prime determinants of performance here. I've chosen 10 million decimal places as a benchmark. You can download it here, simply unzip and run the .bat file, and wait for the results to be appended to the text file.
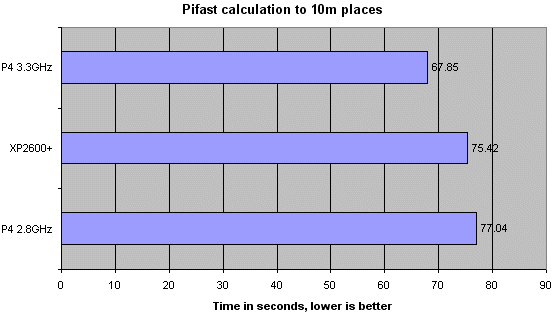
The P4 2.8GHz and enhanced XP2600 are almost tied. The enhanced XP's increased bandwidth helps it stay competitive here. The 3.3GHz P4 demolishes all previous records in this benchmarks. Strangely enough, the 67.85 seconds that it took are longer than I had expected. I can attribute this to the slacker memory timings that had to be used in this very memory-dependant benchmark.



