Architecture improvements
Looking at Ivy Bridge from a top-level view shows that the fundamental design goes largely unchanged. Like Sandy Bridge, Ivy makes use of a two-chip platform (CPU and PCH), with the CPU portion neatly integrating up to four IA cores, a graphics processor and a memory controller all hooked up to a ring-based interconnect that allows the multiple processors to tap into a shared last-level cache.
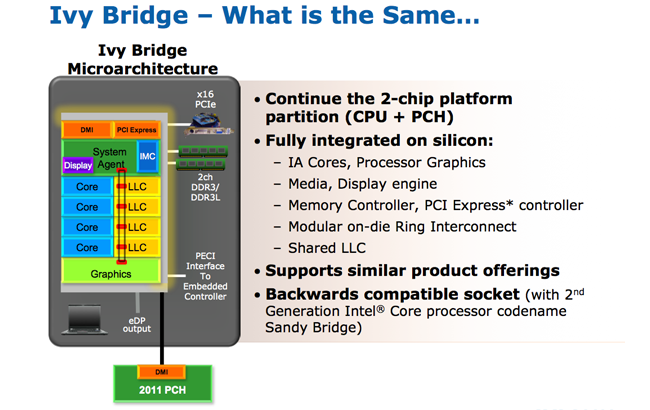
The chip's make-up is in keeping with existing Sandy Bridge parts, right down to the amount of integrated cache - each IA core is exclusively served by a 64KB L1 and 256KB L2 cache, with a last-level cache of up to 8MB shared across all cores, the graphics processor and system agent.
And, as expected, Sandy Bridge features such as Hyper Threading, Turbo Boost and QuickSync have all followed through to Ivy Bridge. In many ways, this is Sandy Bridge built on a 22nm process that enables higher performance and lower power consumption, but there are a couple of key improvements under the hood.
Instruction Set Architecture Enhancements
Expanding on Sandy Bridge's implementation of double-width Advanced Vector Extensions, Ivy Bridge brings two new Float16 format conversion instructions into the mix; VCVTPH2PS and VCVTPS2PH. These support conversion between the 16-bit (compressed) floating point memory format and the 32-bit single precision formats (either 256-bit AVX or 128-bit SSE), allowing for a higher dynamic range in the same memory footprint.
AMD and Intel have been engaged in an ISA war, where hardware improvements are designed to make it easier and faster for code to run on each company's CPUs. With reference to the above-mentioned instructions, AMD mooted a CVT16 instruction set some time ago, but now that Intel has implemented a practically identical method in Ivy Bridge, VCVTPH2PS and VCVTPS2PH are set to become standard. AMD had the initial thought, it seems, but it's Intel's influence that will make it a reality for software developers.
On top of this, the REP MOVSB and REP STOSB instructions have been improved to offer more consistent performance across string lengths, and four new ring-3 instructions have been incorporated to provide fast access to the FS and GS base registers.
In order to improve instructions per clock (IPC), Ivy Bridge removes MOV instructions from the execution pipeline (they now take place at the register renaming stage), a next-page prefetcher has been introduced to enable prefetching across a 4K page boundary and a pipelined divider is in place to improve throughput of divide-related computations.
Don't worry if these upgrades sound unfamiliar, just know that they're designed to enable the CPU to respond to your instructions that little bit quicker.
Added Security
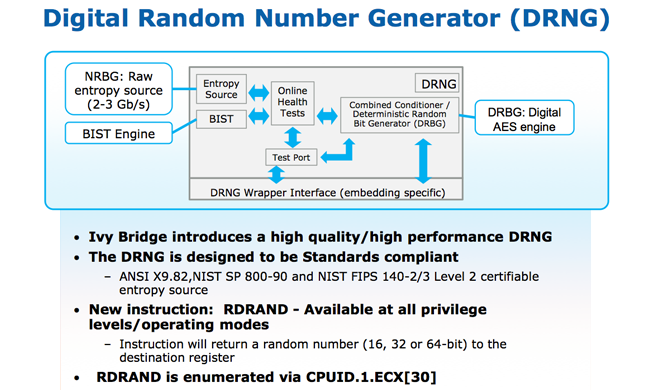
Continuing to run through the underlying improvements, the Ivy Bridge architecture also introduces two new security enhancements.
The first, dubbed the Digital Random Number Generator (DRNG, pictured above), is a high-speed and standards-compliant number generator used to generate cryptographic keys.
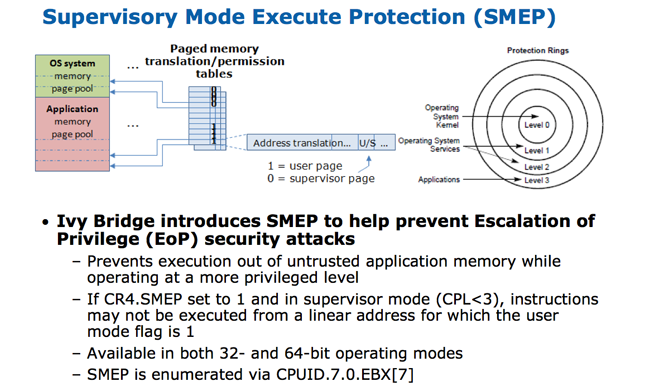
The second, dubbed Supervisory Mode Execution Protection (SMEP, pictured below) is designed to protect against Escalation of Privilege (EoP) attacks by preventing access to user mode pages when running at a higher privilege level.