





We all know how the old argument goes - Windows is full of holes, Linux is built like Fort Knox and OS X makes anti-virus software unnecessary. None of this might matter for much longer though, as computer scientists at ESIEA in Paris have shown that it could be possible to create malware that can target a specific CPU, regardless of the OS.
Though these kind of attacks are still some way off, the team, led by Anthony Desnos, demonstrated (PDF) a way in which they could theoretically work. The hard part, apparently, is to identify which processor it is that's being used. To achieve this, the researchers took advantage of the unique way in which different chips - or at least families of chips - calculate certain values.
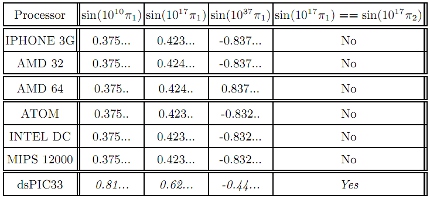
In this case, the team calculated sin(10^χ π) for various different numerical values of π, which enabled them to pinpoint a specific family of processors. At that point it would just be a matter of running the malicious code on the CPU.
The researchers commented that, using this technique, it would be possible to "enable far more precise and targeted attacks, at a finer level in a large network of heterogeneous machines but with generic malware".
Even though the team has yet to find a method of identifying specific processors, it does open the door for further research into OS-independent malware. It also raises a lot of further issues, including how to defend against such an attack and the reality of a virus targeted against mobile devices.
For those interested, Technology Review offers a more detailed analysis of the paper.







