





A little over a year ago HEXUS reported upon Lyrebird, an AI powered API that could "copy the voice of anyone". All it needed was one minute of source audio, of a subject speaking, then it could be used to create completely new speech in that same person's voice. What if you could easily synthesize a subject's portrait video to match the words being spoken with perfectly synced mouth movements, eye movements, and expressions? A team of scientists have published a research paper and video demonstrating this exact ability. They call the technique Deep Video Portraits (PDF).
In the video above you can see a demonstration of Deep Video Portraits in action, and some of the techniques behind it. Basically the AI can take a source sequence and map it to a target video to create a re-enactment. The researchers claim this is the first time a method has been able to transfer these types of movements between videos. They can "transfer the full 3D head position, head rotation, face expression, eye gaze, and eye blinking from a source actor to a portrait video of a target actor". If you watch the above video closely you will see that even the background and shadow of the subjects in the video are consistently synthesized to match the new head motions. The method is outlined below (click to zoom image).
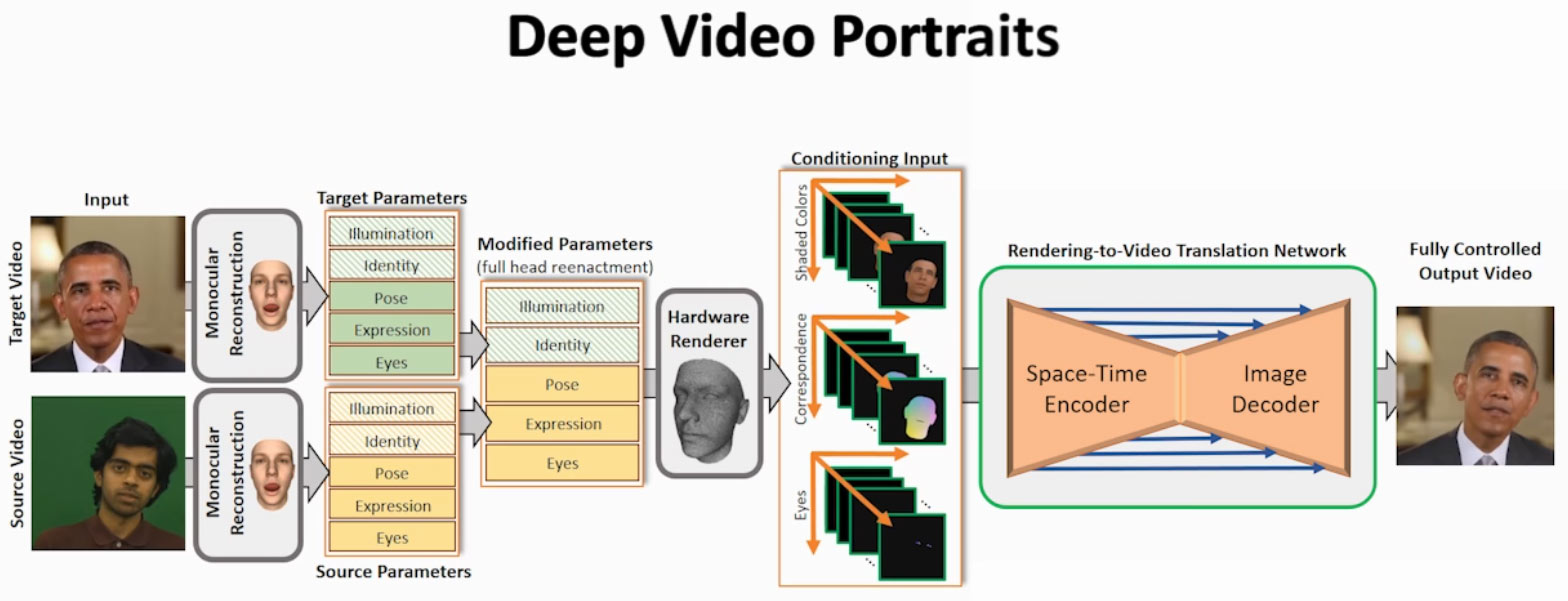
Various parameters can be toggled and the end result changed. Below is an example 'expression only re-enactment'. Elsewhere in the demonstration video you can see the cideo sequence being tweaked manually with the mouse - moving the re-enactment's head position for example.

Earlier this year there was some controversy about the world of 'deepfakes', where often explicit videos were being shared with the adult film actors' faces swapped for those of more mainstream celebs. Sites / portals such as Reddit, Pornhub, and Twitter cracked down on this type of video. TechCrunch reckons the new Deep Video Portraits AI is both "way better (and worse)," as its technology is so refined, yet its potential to deceive far greater.
The research paper was authored by researchers at Technicolor, Stanford, the University of Bath, the Max Planck Institute for Informatics, and the Technical University of Munich. The work has been submitted to the SIGGRAPH conference, which will take place in August.







