





Changes under the hood
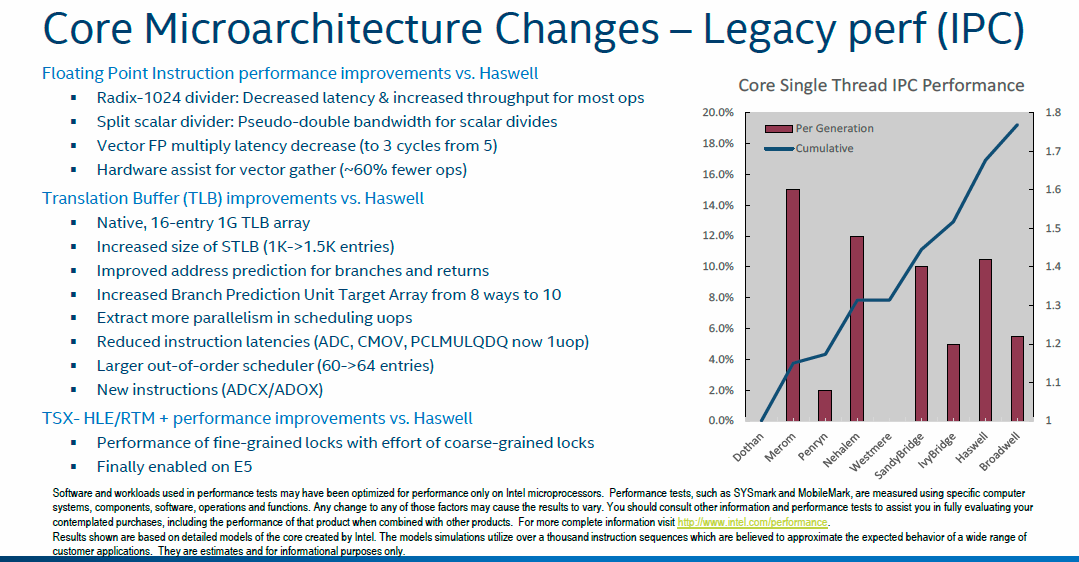
Remember that we said most of the marginal gains in performance on a core-per-core basis were derived from improvements in architecture. This slide represents a recap of just what Broadwell, as a base architecture, has to offer. Notable improvements include the ability to run Transactional Synchronization Extensions on the E5, useful for speeding-up database transactions, and this is important since it was disabled in most of the previous generation due to a hardware bug.
Other improvements are standard fare for one generation to the next. It almost goes without saying that buffers are enhanced, prefetching and the branch-prediction unit is revamped and the scheduler given a boost. The same is true of high-performance Xeons as on relatively low-power processors such as the ARM Cortex-A72 which also benefits from the same low-hanging fruit gains.
Hardware-based cryptography is targeted by the addition of two new instructions - ADX and ADOX - promising significant speed-up in commonly-used keys. Security, in general, sees far more emphasis this time around, too.
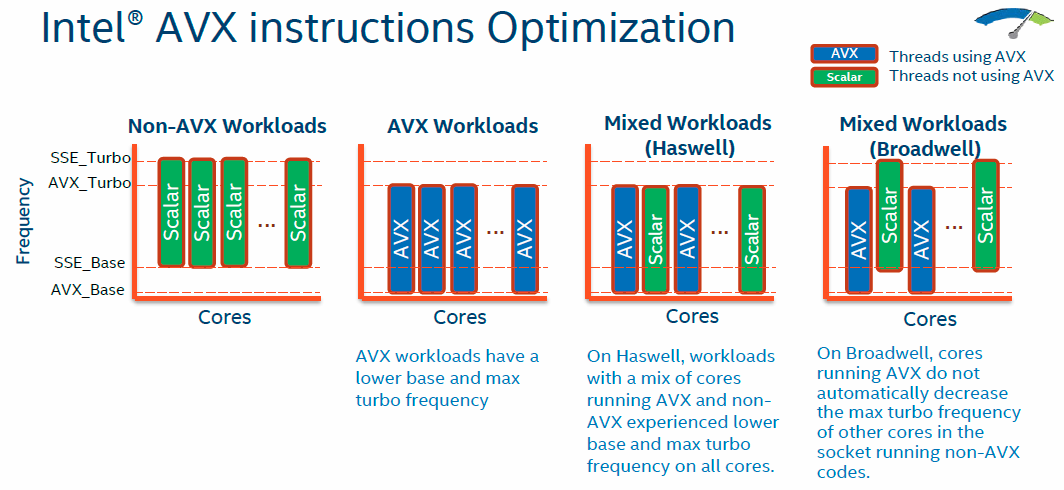
Turbo frequencies only tell you so much about how a processor performs under various loads. Intel has taken the opportunity to improve the way in which the Xeon E5 v4 performs when processing mixed-usage threads - AVX and non-AVX (scalar) - by enabling the Broadwell processors to run non-AVX code at higher speeds at the same time as concurrently working on AVX code.
This was limited on Haswell because AVX workloads exacted the maximum amount of performance from the chip so it was felt that having higher speeds on scalar threads didn't make sense. That limitation goes with Broadwell, so while it's not an everyday occurrence to run the two types of workloads together, Broadwell manages to keep overall performance a touch higher. Note that pure AVX workloads still run at a lower peak speed than their scalar counterparts.
Then there are other general improvements in performance for specific scenarios. Virtualisation, for example, is given a helping hand by posted interrupts, meaning that they're bunched together and delivered in one fell swoop rather than having the virtual machine exit each and every time. This coupled with a reduction in entry/exit latency of around 20 per cent - 400 cycles vs. 500 cycles on Haswell - should offer a better virtualised experience.
Intel is also taking the opportunity with the E5 v4 launch to issue upgraded software called Resource Director Technology (RDT) that, for Broadwell-EP, monitors cache and fine-grained memory usage on a per-thread/app basis within normal and virtual machine environments. The point of RDT is that it should provide better information for scheduling and load balancing by understanding just how the last-level cache is occupied and working on a continual basis. Point is, with up to 55MB of LLC and lots of bandwidth from a quad-channel memory architecture running at 2,400MHz, Intel believes there needs to be a better way in which to optimise workloads; RDT is a first step in that aim.




{kind=link}
{kind=link}