





HEXUS has previously reported on the development of the Cerebras wafer scale engine – the world's largest computer chip at 462cm2, which is the square size limit for a 300mm wafer. The chip, slightly larger in the hand than a typical iPad, was first announced over a year ago, and Cerebras started to tease a second gen model in August this year. Now it has provided some performance indicators for the first gen CS-1 and is boasting about setting records in computational fluid dynamics.

Cerebras has been closely collaborating with researchers at the National Energy Technology Laboratory (NETL) to see how its startlingly different technology can be applied, and accelerate solutions in tasks like "forecasting the weather; finding the best shape for an airplane’s wing; predicting the temperatures and the radiation levels in a nuclear power plant.." and others.

NETL already has a supercomputer at its disposal, the Joule 2.0. If you click the link you can find more info about the Joule 2.0, but in brief it is an HP made supercomputer which is Intel Xeon based, employing a multitude of processors to wield 86,400 cores at scientific tasks and problems, as well as over 300,000GB of RAM. To provide further context Joule 2.0 is the 81st fastest computer system in the world, according to the Top500. Joule 2.0 has dropped from 52nd slot gradually since its introduction in 2018.
CS-1 is over 200x faster than Joule 2.0
A Cerebras CS-1 wafer-scale chip is about 60x larger than large conventional CPUs or GPUs. This single wafer hosts almost 400,000 processor cores, each with its own private memory (48k SRAM) and a networking 'router' component connected to the four nearest cores. In tests undertaken by Cerebras and NETL researchers they found that the CS-1 can works its way through the types of problems mentioned in the intro 200x faster or more.
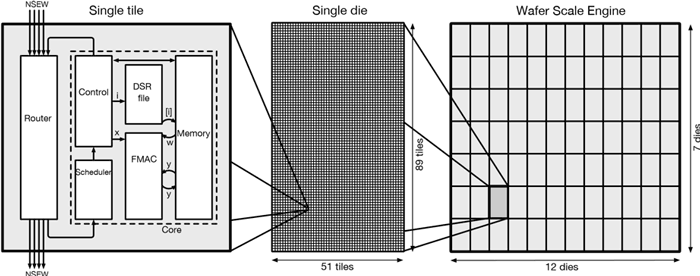
The Cerebras blog provides a deep dive behind the technology which helps it thrust ahead but thankfully it also provides some short and sweet bullet points explaining the CS-1's advantages, as follows:
Three key factors enabled the successful speedup:
- The memory performance on the CS-1.
- The high bandwidth and low latency of the CS-1’s on-wafer communication fabric.
- A processor architecture optimized for high bandwidth computing.
Cerebras says it will be sharing further findings later this month at SC20. It hopes its pioneering wafer scale chips will provide major breakthroughs in scientific computing. We can't wait to hear about what it expects of CS-2 with its 850,000 scores, more details of which will be coming shortly.
|
WSE gen 1 (CS-1) |
WSE gen 2 (CS-2) |
|
|
Transistors |
1.2 trillion |
2.6 trillion |
|
AI cores |
400,000 |
850,000 |
|
Chip area |
46,225mm² |
Not confirmed |
|
TSMC node |
16nm |
7nm |
|
SRAM built-in |
18GB |
Not known |







