





R580: Vertex Processing and 'Ultra Threaded' fragment dispatch
If you managed to catch our recent look at Radeon X1300 PRO and X1600 XT, most of what we'll go over here will be familiar. Our examination of RV515 and RV530 for that piece showed that RV515 is roughly a quarter of an R520 in terms of functional blocks and processing power. That scale applies to RV530 and R580 in a broad sense, R580 quadrupling what RV530 is capable of for the most part.Let's dig right in and explain what that means.
Vertex processing
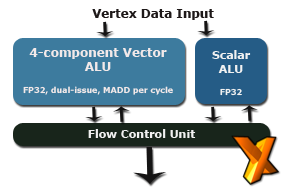
A modern programmable graphics processor starts the rendering process by passing geometry data to be shaded through its vertex units. R580 contains the same collection of eight SIMD, dual-issue vertex processors as R520, each capable of a basic '5D' MADD per cycle, across vec4 and scalar FP32 ALUs. Each unit is capable of single-cycle sin and cos instructions, and purports to support the VS3.0 specification as part of DirectX Shader Model 3.0.
That's not quite true, since the vertex processors in R5-series GPUs can't texture. That's to say there's no dedicated texture units, made up of texture address and texture sampler units, attached to the vertex processor hardware. Shader Model 3.0 mandates that VS3.0 units have that ability. ATI work around it by giving the fragment hardware the ability to render to a vertex buffer, using their texture units to do the processing on behalf of the VS hardware.
Developers then check for render-to-vertex-buffer (R2VB) capability, create the buffer, set a magic LOD value in the shader, ask for processing to be done and read back from the buffer. An extra code block to maintain for the developer, outside of any official interface in D3D9, but a small and effective way to allow the texld instruction, with no filtering, in a developer's vertex shader programs on R5-series chips.
Each vertex processor also has dedicated branching logic, supporting static and dynamic branch instructions in the developer's vertex shader programs compliant with the VS3.0 specification. VS branch penalty is low in R5-series hardware, allowing the developer to process geometry in creative and efficient ways not offered by the old fixed-function geometry pipeline bare generations ago.
R580, like the other R5-series chips, supports early geometry discard via depth test and a hierarchical Z-buffer, and all geometry that outputs the vertex hardware after shading is sent to the rasteriser for converstion into fragment data.
'Ultra-Threaded' Dispatch Processor and register array
Fragments to be processed are scheduled by ATI's new dispatch processor. Like the unit in R520, RV515 and RV530, it has control over a large patch of fragment threads, scheduling them for processing by the fragment processors. Batch size in R580 is 48 fragments, processed 2x2, 4 deep, 3 wide. The three-wide is important as we'll explain on the next page.Thread count is still 128 per quad of units, for a grand total of 512 threads maintained by the dispatch processor simultaneously. The large number of threads and small batch size means that - as we explained with RV515 - the dispatch hardware is able to keep the large number of fragment ALUs and their texture units busy as much as possible.
Efficiency is what ATI are obviously aiming for with the thread granularity and the small batch size, and combined it means that branching penalties are minimised. When you have schedule execution of another branch, or process all branches depending on what the shader program is doing, you want that extra processing penalty to be as small as possible.
To assist the maintenance of so many relatively tiny threads, R580 maintains two 4-component FP32 registers per fragment, per thread, in its general purpose register array. Adequate in-process storage is also key to ATI's 'Ultra-Threaded' dispatcher to work correctly. ATI strike a balance between transistor budget and available in-process storage with the same two full FP32 registers per fragment, per thread of storage that R520, RV515 and RV530 have.
It's no more per-fragment space than you'll find in chips that have been around for a while, but given the in-flight count of fragments it adds up to a 768KiB register file, multi-ported for simultaneous reading and writing, given the batch size.
Fragment management then leads on to fragment processing and texturing.



