





Let's change graphics forever
What constitutes a modern graphics card?
This is the crucial question that'll shape how we think about graphics cards in the future. It's now simply not enough to release a new design that excels in munching gaming-orientated shaders and producing pretty-looking pixels. A modern GPU needs to be truly excellent at both gaming and GPGPU (General Purpose Computation on Graphics Processing Units) work. These two somewhat complementary facets are akin to the server, desktop and notebook roles played by the current batch of CPUs; insofar as they need to be multi-purpose.
AMD and NVIDIA now design for high utilisation, high throughput scenarios where gobs of multitasking is taking place, be it for games or GPGPU. NVIDIA's Fermi architecture, as found on the GeForce GTX 580, does this well, and now AMD is introducing its own best-of-both-worlds architecture that's dubbed Graphics Core Next.

GCN Compute good, VLIW bad
We know that Tahiti has a greater number of shading cores than Cayman but they are also arranged quite differently. While more than adequate for gaming, AMD's VLIW4 (Very Long Instruction Word) design, as found on Radeon HD 6970, has certain shortcomings when non-gaming apps - GPGPU, therefore - need to maintain a high utilisation rate. We can zoom into one of Tahiti's 32 Graphics Core Next Units and uncover more.
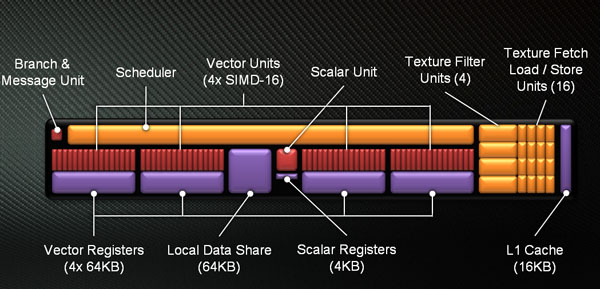
What you're looking at is a self-contained unit - and that's very much key here - that includes four 16-wide SIMD vector blocks (the red ones), plus a scalar unit and registers in the middle and a general, per-core scheduler at the top. So why switch from something that ain't broke - VLIW4/5 - to a brand-new design, thus factoring in all the uncertainly and risk that such a move entails? The answer is disarmingly simple, as it's all about encouraging professional users to take up the Radeon GPUs as general-compute devices.
You see, VLIW provides a solid foundation for pushing graphics code through hardware. The same instructions can be thrown at the shader-blocks and executed on the SPUs in parallel, for different data (hence the SIMD reference), and it all works nicely as developers have streamlined compilers that produce just the right kind of throughput. Indeed, if this GPU was solely for graphics, which is accurate in an historical sense, AMD would have persevered with the mature VLIW setup. Heck, it wouldn't have moved from VLIW5 to VLIW.
But, and it's a crucial but, VLIW, while fine for graphics, isn't easy to code for in a general-compute sense. There are so many other factors to consider in the eclectic GPGPU space that developers need a broad, cleaner, self-sufficient architecture. They need standardisation and simplification, and this is where Graphics Core Next comes in, or, more precisely, where VLIW falls down.
Recent history shows us that AMD's been pulling and pushing the VLIW setup to better fit in the workflows demanded by GPGPU code. The company has added a bunch of GPGPU goodies in the move from Cypress's VLIW5 to Cayman's VLIW4 architecture - that's Radeon HD 5870 to HD 6970 for most folk - but there's only so much you can hammer a square peg into a round hole. There exist technical limitations that cannot be overcome with a tweak or two. It's time to start a-fresh and evaluate just what's important.
Graphics Core Next is this new start. Conceived three years ago and now seeing the light of day, it's all about being efficient everywhere, at all times. From a high-level sense, GCN's compiler is fundamentally overhauled, and it's now significantly easier to disassemble and debug code, allows for more-granular optimisation of shaders, which are all key in the HPC environment.
Made for compute

And another nicety of this GCN design is that there's less of a chance of stalling the GPU. In a VLIW design, the compiler in the driver schedules per-unit work (or wavefronts, in AMD-speak) ahead of time. They're then sent packing off to the shader-cores for processing. But what happens if a wavefront processed near the end is reliant on the outcome of another previously-processed wavefront? There's not much you can do once the instructions have been dispatched, the scheduler has done its work and the GPU is inefficient for a while as there's no out-of-order execution available; it's a fire-and-forget approach. This situation doesn't occur too often in gaming code but can be prevalent with GPGPU workloads where workload dependencies can exist.
With GCN, each wavefront can be independently handed over to a compute unit and its scheduler, removing dependency and enabling stable, predictable performance. These units can communicate with one another and calculate the optimum method of processing code. And because you're less reliant on an external compiler, which may introduce complexity, GCN makes it easier to debug and disassemble. That's the theory, anyway.
Further, and much along the same lines as NVIDIA, AMD boosts the ability to run multiple kernels at once, and by now you'll know that the GCN architecture is to thank for this. Cayman has it too, albeit in a much-limited form, due to the rigid VLIW architecture.
Rather than continue to get bogged down in the technological mire that further explains GCN vs. VLIW - or Radeon HD 7970 vs. HD 6970 - understand this: the new chip uses a far more elegant design to achieve high throughput for GPGPU tasks, though, like-for-like, it may be no quicker for graphics than a traditional VLIW architecture.
Coming on the familiar ground again now, four texture units per GCN core lead to 128 in total, and AMD keeps the GPU humming along by increasing the speed of the various L1 and L2 (768KB) caches. Remember how we said it was more NVIDIA-like? Fermi taught us a few tricks; AMD's also used them.



