





Nvidia CEO Jen-Hsun Huang used his keynote at the GDC2016 today to announce the Tesla P100 GPU card and hailed it as "the most advanced accelerator ever built". This GPU accelerator marks a milestone as it is the first to be based upon Nvidia's 11th generation Pascal architecture. It is expected that the new GPU card will be leveraged to build a new generation of data centres capable of deep learning feats that will go further than ever before in meeting scientific challenges such as "finding cures for cancer, understanding climate change, building intelligent machines".

Keeping his foot on the hyperbole accelerator Huang said the Nvidia Tesla P100 GPU was based upon five "miracle" technological breakthroughs. The breakthroughs were listed as follows:
- Nvidia Pascal architecture for exponential performance leap - A Pascal-based Tesla P100 solution delivers over a 12x increase in neural network training performance compared with a previous-generation Nvidia Maxwell-based solution.
- Nvidia NVLink for maximum application scalability - The Nvidia NVLink high-speed GPU interconnect scales applications across multiple GPUs, delivering a 5x acceleration in bandwidth compared to today's best-in-class solution. Up to eight Tesla P100 GPUs can be interconnected with NVLink to maximize application performance in a single node, and IBM has implemented NVLink on its POWER8 CPUs for fast CPU-to-GPU communication.
- 16nm FinFET for unprecedented energy efficiency - With 15.3 billion transistors built on 16 nanometer FinFET fabrication technology, the Pascal GPU is the world's largest FinFET chip ever built2. It is engineered to deliver the fastest performance and best energy efficiency for workloads with near-infinite computing needs.
- CoWoS with HBM2 for big data workloads -The Pascal architecture unifies processor and data into a single package to deliver unprecedented compute efficiency. An innovative approach to memory design, Chip on Wafer on Substrate (CoWoS) with HBM2, provides a 3x boost in memory bandwidth performance, or 720GB/sec, compared to the Maxwell architecture.
- New AI algorithms for peak performance -New half-precision instructions deliver more than 21 teraflops of peak performance for deep learning.
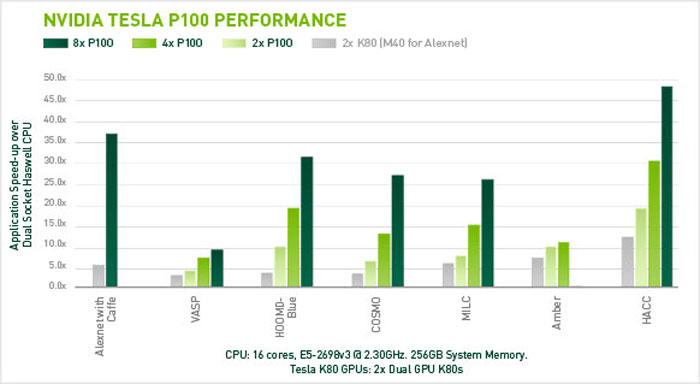
It was claimed that a Tesla GPU with NVLINK will deliver up to 50X performance boosts for data centre applications (see chart above for comparison to Intel Haswell based servers).
Raw performance numbers for the P100 are as follows; 5.3 TeraFLOPS double-precision, 10.6 TeraFLOPS single-precision, 21.2 TeraFLOPS half-precision performance, 160GB/s interconnect bandwidth with NVIDIA NVLink, and 720GB/s memory bandwidth with its 16GB of unified CoWoS HBM2 Stacked Memory.
Nvidia DGX-1
Launching alongside the Tesla P100 is Nvidia's DGX-1 Deep Learning System "supercomputer in a box". The DGX-1 uses eight Tesla GP100 GPU cards with 16GB per GPU, providing 170TFLOPS (half precision performance) from its 28,672 CUDA cores. This machine also packs dual 16-core Intel Xeon E5-2698 v3 2.3GHz processors, 512GB of DDR4 RAM, 4x 1.92TB SSD RAID, Dual 10GbE, 4 IB EDR networking, and requires a maximum of 3,200W. Nvidia's DGX-1 measures 866D x 444W x 131H (mm) and weighs 60Kg (134lbs). Again, compared to an Intel Xeon E5-2697 v3 based processing solution, the DGX-1 offers 56X more performance in TFLOPS and 75X faster training for artificial intelligence.

It is intended that the DGX-1 will be used by firms hoping to accelerate deep learning and is thus supplied with software, in a turnkey solution, to undertake such tasks. Software bundled with the DGX-1 includes; the NVIDIA Deep Learning SDK, the DIGITS GPU training system, drivers, and CUDA for designing the most accurate deep neural networks (DNN). The Ubuntu Server Linux OS is installed to support this software.

Already Nvidia is boasting that Massachusetts General Hospital is one of the first customers using the DGX-1 for its clinical data centre. The AI will be deployed at the hospital to learn about and diagnose heart disease using radiology and pathology data and an archive of 10 billion medical images. Furthermore 'AI industry leaders' such as Facebook, IBM and Baidu have already voiced support for the DGX-1 as one of the first of a new class of servers.
The Tesla P100 is in volume production now with the first wave of production earmarked for DGX-1 supercomputers. DGX-1 nodes will become available in June for $129,000.







