





As Google relies heavily on compute-intensive machine learning for its core activities it has designed and rolled out its own Tensor Processing Unit (TPU) accelerator chips in recent years. The need for such a chip became evident about six years ago with the growth in computational expense due to technologies like Google voice search taxing the deep neural net speech recognition systems.

With help from the likes of Norman Jouppi, one of the chief architects at MIPS, Google introduced servers packing its TPU chips back in 2015 (quite a quick development cycle). The new processors were designed with the particular focus of AI workloads and are thus ASICs (application-specific integrated circuits). Now, for the first time, Google has measured the performance of its TPU systems and compared them to contemporary alternative processing solutions.
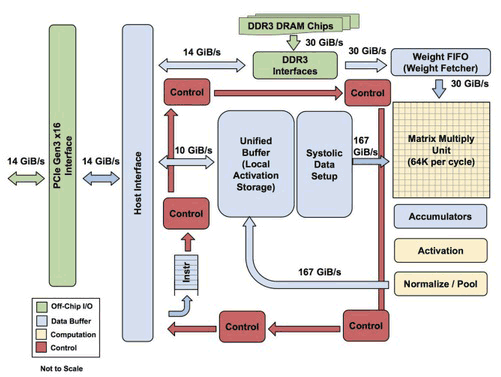
In a blog post, Google sums up the benefits of its TPU over contemporary GPUs and CPUs as follows:
- On our production AI workloads that utilize neural network inference, the TPU is 15x to 30x faster than contemporary GPUs and CPUs.
- The TPU also achieves much better energy efficiency than conventional chips, achieving 30x to 80x improvement in TOPS/Watt measure (tera-operations [trillion or 1012 operations] of computation per Watt of energy consumed).
- The neural networks powering these applications require a surprisingly small amount of code: just 100 to 1500 lines. The code is based on TensorFlow, our popular open-source machine learning framework.
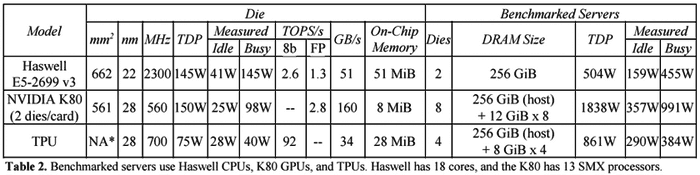
TOPS/s = tera-operations per second
Jouppi talked to The Next Platform about the TPU design. Interestingly, the Google distinguished hardware engineer explained "The TPU is programmable like a CPU or GPU. It isn’t designed for just one neural network model; it executes CISC instructions on many networks (convolutional, LSTM models, and large, fully connected models). So it is still programmable, but uses a matrix as a primitive instead of a vector or scalar." This processor is nearer to the spirit of an FPU than a GPU, added Jouppi.
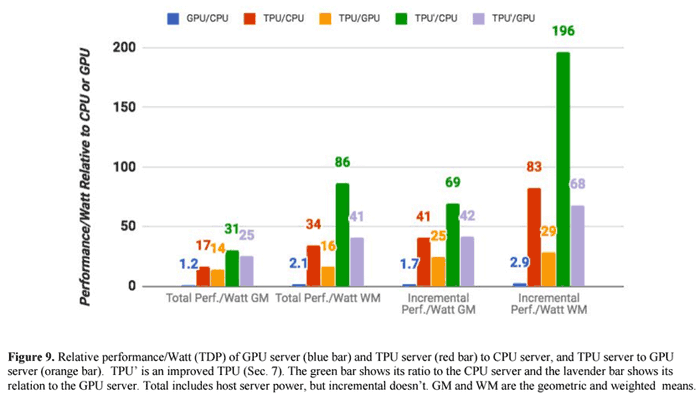
For further illumination regarding the TPU performance and efficiency a couple of graphs would be useful. Luckily Google has provided some and you can glance over them, above and below.
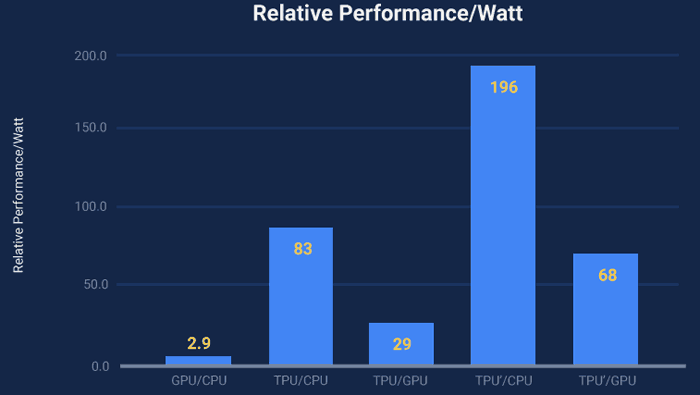
The TPU' is an improved TPU
As well as the above cited common workload example of voice search, which prompted the design of this ASIC, the TPU powered servers are of great utility for; translation services, image search and indexing, cloud vision and more.







