





Micron will launch its GDDR6 memory next year, according to an exclusive report carried by Fudzilla. The new generation memory will offer twice the bandwidth of GDDR5 and "will be the company's answer to HBM". The development, launch schedule and some key specs of GDDR6 have been confirmed by the Director of Micron's global Graphics Memory Business, Kristopher Kido, says the source.
Looking at the important key performance specs of GDDR6, users will benefit from memory bandwidth of 10 to 14Gb/s. That compares very well, as much as doubling up, to the 7.0Gb/s of 4Gb GDDR5. The promised 8.0Gb/s data rate of 8Gb GDDR5 is also not coming close to reaching GDDR6.

Importantly for its adoption by the industry GDDR6 brings not just extra speed and bandwidth, but a component form factor which is similar to GDDR5. As Fudzilla reports, this will reduce "the burden and complexity of design and manufacturing," new graphics products using GDDR6.
Since HBM is still in short supply and HBM 2.0 in development GDDR6 could be a very worthwhile stopgap for the industry in the next year or so. Looking at 2016 we will have 14 and 16nm GPUs emerging and new fast memory technologies coming into play at the high end and perhaps lower down thanks to GDDR6.
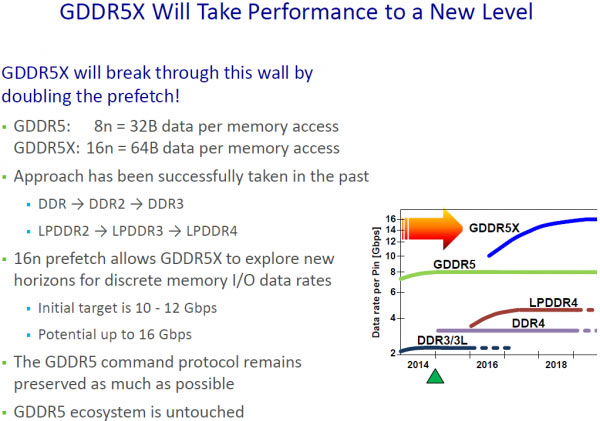
HEXUS first reported on the leaked slides showing Micron's development of GDDR5X back in October (as in the example above). It appears that the magnitude of the improvements on offer (and the marketing department) has pushed for the adoption of the designation of GDDR6 for this new faster and higher bandwidth memory.







