





When we first introduced NVIDIA's Kepler GK104 architecture, earlier this year, we noted that the firm had sacrificed double-precision floating-point performance, in exchange for smaller, cheaper and cooler chips, factors typically of more importance in the gaming world.
For professionals, NVIDIA promised the Kepler GK110, which would offer a three-fold double-precision performance boost over the Fermi of yesterday, however, even now, NVIDIA still advertises only the GK104-based Tesla K10 - which offers significantly less double-precision performance than its Fermi counterparts.
This isn't to say that the Tesla K10 isn't an impressive beast; in fact, if single-precision is all you require, it'll pump out more than thrice the performance of a Fermi card in a similar power footprint, however, it's about time we saw just what the architecture can do when it comes to high-precision calculations.

Though not currently advertised on NVIDIA's website and thus having fallen mostly under the radar, the GK110-based Tesla K20 does, in fact, exist and, is out there crunching numbers. It was recently revealed that Cray had updated its Jaguar XK7 supercomputer with 18,688 Tesla K20 units, subsequently renaming the unit to Titan. At over 20 petaflops of performance, Titan is ten times faster and five times more energy efficient than it had been prior to the upgrade, where it had previously featured 18,688 16-core Opteron 6274 processors.
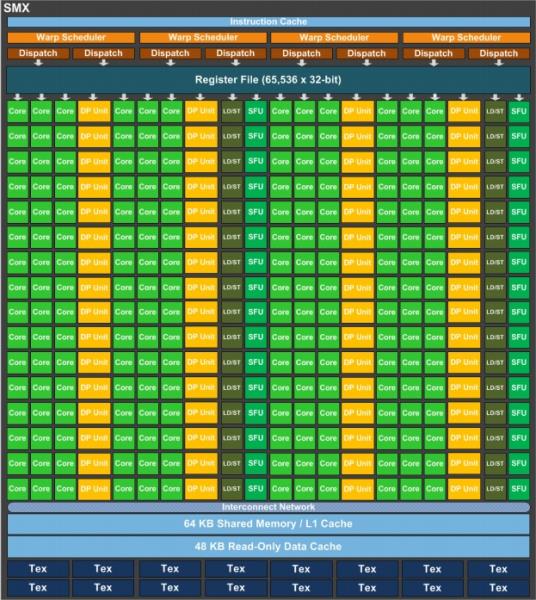
NVIDIA has been trickling details over the months and we can in fact confirm most of the Tesla K20's specifications. Perhaps the most interesting factoid is that the GK110 chip features a jaw-dropping 7.1 billion transistors, making this NVIDIA's largest chip ever, in fact, twice the size of the firm's Kepler GK104.
| Tesla K20 | Tesla K10 | |
| CUDA Cores (FP32) | 2,496 | 2 x 1,472 |
| CUDA Cores (FP64) | 832 | 2 x 64 |
| Core Speed | 705Mhz | 745MHz |
| Memory Bus Width | 320-bits | 2 x 256-bits |
| Memory | 5GB GDDR5 | 2 x 4GB GDDR5 |
| Memory Speed | 4.2GHz | 5GHz |
| Single Precision Performance | 4,577 GFLOPS | 5,340 GFLOPS |
| Double Precision Performance | 1,173 GFLOPS | 190 GFLOPS |
| Power Consumption | 225W | 250W |
From the specifications table and the image above, we can see that the GK110 features in each SMX, 192 FP32 and 64 FP64 CUDA cores, 32 Special Function, 32 Load/Store and 16 Texture units. In fact, aside from the additional double-precision units, the SMX is architecturally identical to the GK104 Kepler at a high-level, aside from the absence of the PolyMorph Engine utilised in graphical tessellation.
The GK110 isn't a complete carbon copy, however. It features 15 SMXs vs the 8 of the GK104, full support for ECC memory and CUDA compute standard 3.5 (features such as increased registers, dynamic parallelism etc).
With such an impressive beast, which in a worst-case scenario offers around twice the FLOPS per Watt of a comparable Fermi card, why hasn't NVIDIA released the K20? We suspect that, with 7.1 billion transistors, yield may be an issue and, we also know that CUDA 5, which offers full support for the new architecture, has only just been released. Hopefully it won't be too much longer before you can pop down to the e-shop and snap-up one of these compute power-houses.







