





After our own reader-base flagged the matter in comments last week, we began to investigate a rumour that there was a registry patch in the works that could offer a 40 per cent performance increase for AMD's Bulldozer CPUs.
Though, quite reasonably, the figure of 40 per cent appears to be somewhat exaggerated we have found both merit and proof that the Bulldozer does indeed suffer a performance penalty under scenarios with only a few intensive threads, that is an issue grounded entirely in software.
This all relates to the Bulldozer's unique shared architecture where two cores share some of their resources in what's known as modules. If we were to talk about a hyper-threading Core i7, typically an operating system's scheduler would assign intensive threads to separate real cores, before assigning less intensive threads to the virtual hyper-thread cores. In the case of the Bulldozer, schedulers see each core as a completely independent entity and do not recognise the shared relationship of cores and their modules.
This leads to various scenarios:
· Two intensive threads are placed on the same module, fighting for resources when there are spare modules or modules running only non-intensive threads.
· Two tightly interconnected threads that must share information are placed on separate modules, leading to a large communication delay between the two threads.
· Non-intensive threads are spread across multiple modules, preventing the Bulldozer from powering-down unused modules, affecting both energy-efficiency and the ability to employ Turbo Boost.
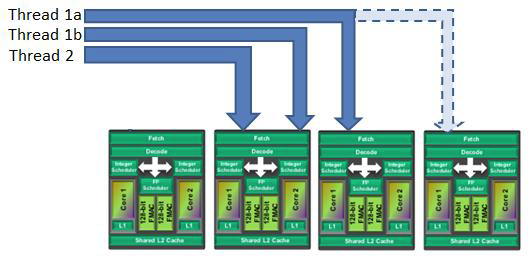
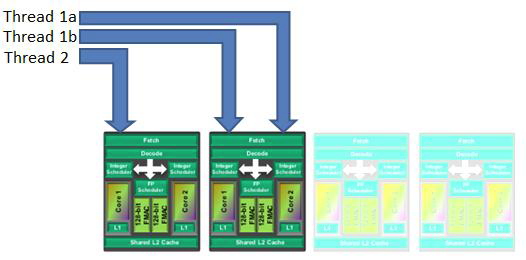
This all goes some way to explaining the poor performance of the Bulldozer in benchmarks that were not thread-heavy. We had never expected to see exceptional low-thread performance from an octo-core devise; but had found the Bulldozer's advanced 3.6GHz cores occasionally bested by the 3.3GHz cores of its hex-core Phenom II 1100T brother.
AMD confirms that this issue is real in a whitepaper, stating that both modifications to compilers and schedulers would be needed to maximise performance of the Bulldozer architecture. Full support for AVX and other new vector instructions has only been available since Visual Studio 2010 Service Pack 1 and compiler awareness for a shared-module architecture is still not present.
Likewise, the Windows 7 scheduler lacks shared-module architecture awareness, leading to the scenarios listed above. In simple tests performed by techreport.com, it was discovered that by setting a scheduler affinity, causing all threads to be placed on separate modules, a 10 to 20 per cent increase in performance could be observed over all but one of the test cases. This test only tackles the first scenario listed above and a fully-aware scheduler would be required to deal with all of the possible situations.
Windows 8 preview sports an enhanced work-in-progress scheduler that does have this awareness. In AMD benchmarks there was an average five per cent performance increase in real-world gaming scenarios. We stress that these figures are subject to change as Windows 8 is in early development and that enhancements to the scheduler are still being made.

Results certainly vary, with up to twenty percent performance increase observed in synthetic benchmarks with a forced core affinity and up to ten per cent observed in real-world gaming scenarios under an enhanced module-aware scheduler. We suspect this variation is caused by attempting to strike a balance across all of the above scenarios and that perhaps the perfect solution to the Bulldozer's unique architecture has yet to be found.
What we can say with certainty is that if you're looking for performance in the here and now, then the HEXUS benchmarks released earlier this month won't steer you wrong. If you're looking at the future capability of the Bulldozer CPU as a long-term investment, then early results indicate that you'll receive anywhere from two to twenty percent better performance in low-thread scenarios and that's without factoring in compiler enhancement.
We'll be sure to keep a close eye on any new developments.







