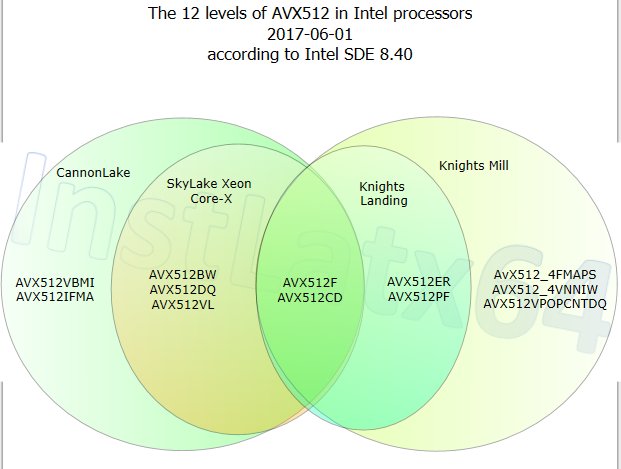
When Intel launches its 10nm Cannon Lake (CNL) and Ice Lake (ICL) processors for consumers it is now expected that they will come packing Advanced Vector Extensions (AVX) 512 instruction compatibility. Anton Shilov from tech site AnandTech discovered that an update to the Intel document for software developers now indicates that AVX-512 and a host of other new non-AVX-512 instructions will be supported by the next gen Intel CPUs sold to mainstream consumers.
AVX-512 was primarily designed to process large amounts of data, thus targeting servers and, to a lesser degree, workstations. This is why the exptensions first appeared in Intel's top-end powerful Xeon Phi processors.The extensions, which are numerous and include AVX512F, AVX512CD, AVX512DQ, AVX512BW, and AVX512VL, can provide significant benefits to activities like encoding, rendering, cryptography, and deep learning. However consumer programs will have to be updated to support AVX-512, to tap into the benefits.

It’s uncertain whether the AVX-512 extensions will be kept in reserve for higher-end consumer desktop processors, like Core i7 CPUs or 'Exteme Edition' consumer CPUs. AnandTech notes that these extensions carry a weight of sorts; adding the extensions has previously resulted in double digit percentage die size increases, extra costs, and also currently lack of consumer applications support.
The Intel Architecture Instruction Set Extensions and Future Features Programming Reference document (PDF) has been published ahead of its hardware releases to allow developers to prepare apps for the arrival of these CPUs with AVX-512. As well as referring to the above document, the AnandTech linked article provides at-a-glance tables showing the propagation of AVX-512 support through various Intel CPU product tiers and generations.