





A fully-fledged processor is far more than just an aggregation of cores. There needs to be a means of connecting the cores to external memory, IO - usually through PCIe or QPI - and the supporting L3 cache. In Intel-speak, this is known as connecting the core to the uncore.
Various companies use an in-house topology that forms this interconnect. In the case of Intel, as it pertains to Xeon processors, this core-wide interconnect is known as the ringbus architecture that was prevalent with the Sandy Bridge architecture way back in 2011.
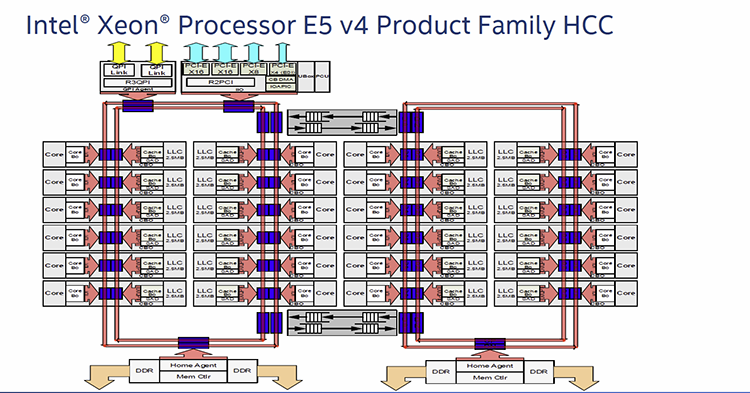
This form of switch-based interconnect works fine on consumer processors with relatively low core counts. However, as the core count rises, ostensibly in the server space, the rings become increasingly more congested and complex. This is why, on the Broadwell-EP-based Xeon chips, Intel adds more rings and associated home agents as cores span from four to 22. Here we're showing how it fits into the HCC family of processors at the upper end of the core scale.
The problem Intel faces is one of ensuring super-fast bandwidth and still-low access latency as core counts rise further. It is this increased core parallelism that leads to potential bottlenecks - memory controllers are contained on each ring, after all, and adding more of those whilst keeping latency down becomes difficult. The upshot is that this future many-core problem has made Intel rethink the entire interconnect philosophy - you wouldn't want eight rings, eight memory controllers, and multiple home agents on a single processor.
Understanding the status quo brings us to the announcement for today. Enter the 'mesh architecture' that is designed and built into the upcoming Xeons in mind.
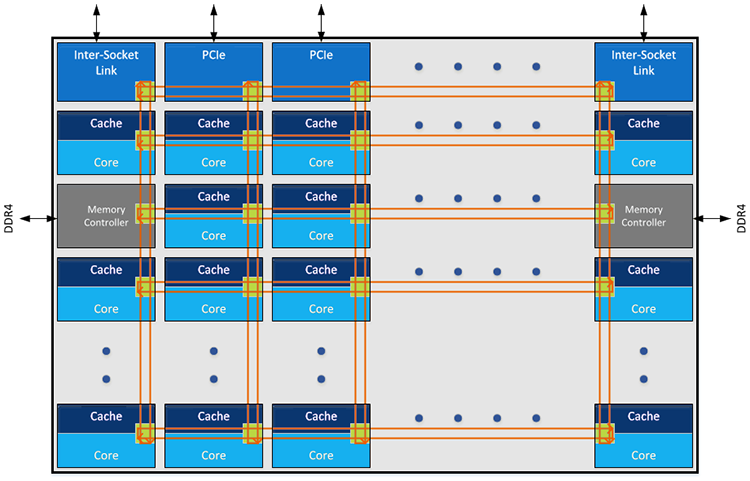
Rather than have an ever-expanding number of rings used to service core counts that will inevitably run way past the present 22, the mesh architecture is, according to Intel, designed in such a way as to be scalable and modular no matter what the eventual core count and memory bandwidth.
This super-simplified diagram, above, shows that each core is connected to each other via a matrix of rows and columns, at crosspoints, with the total number of these wholly dependent on the amount of cores.
But not everything is laid out symmetrically, however. If a core requests information from the L3 cache connected to it vertically, then there is a one-cycle access latency - it is literally right next to it. However, if that core requires information from an LLC that is laid out horizontally and further to the left or right, then three cycles of latency are incurred when spanning adjacent caches. Point is, moving across the entire chip requires more than one hop per core. Intel reckons that even with this limitation latency is kept as low as a ringbus design.
Traffic flows in both directions on each of the rows and columns, and if the final destination is not ready to accept information, it continues to circle the mesh.
Interestingly, power consumption goes down compared to a ringbus architecture, because the mesh has far more intrinsic bandwidth available and therefore can be run at a lower voltage/speed whilst still maintaining the required latency. This ultimately means that some more of the chip's TDP can be shifted to the cores instead, thereby increasing total compute power when compared directly with a ringbus design, according to Intel.
Now, also, the memory controllers reside at the east-west portions of the chip whilst the IO is at north-south; they are not grouped together. The mesh architecture runs at the uncore speed, which is in the region of 1.8GHz-2.4GHz.
Summing up what we've learned thus far, the mesh architecture has been designed from the ground up to ensure that upcoming, many-core Intel CPUs have enough intra-chip bandwidth and IO speed to remove the bottlenecks that would have inevitably have arisen had the ringbus architecture continued on, say, a 28-core part.
The final takeaway is that it is less important on the client Core side, of course, where chip bandwidth isn't really an issue - the mesh architecture is built for scalable Xeons.







