





PRESS RELEASE
By Akhilesh Kumar, Skylake-SP CPU Architect
In advance of the launch of the Intel® Xeon® Scalable Processor platform – Intel’s biggest data center platform advancement in this decade – CPU architect Akhilesh Kumar shares his perspective on Intel’s architectural approach to addressing the needs of the data center, and how that manifests with the Scalable family’s new “mesh” on-chip interconnect.
A key focus in data center architecture is to achieve greater efficiency to get the best return on capital and maximize output within footprint and power constraints to name a few. Processors play a fundamental role in data center optimization, and the impact of processor architecture choices affecting scalability and efficiency can be enormous. Achieving the ideal balance across these vectors requires foresight, creativity and innovation that doesn’t come overnight.
Decades of architecting purpose-built data center CPUs and platforms is reflected in Intel’s broad product portfolio. Generation upon generation, Intel is continually innovating core compute capabilities to improve processor performance. But our work doesn’t stop there. Just as important are the advancements in connectivity and scalability among all of the cores, fine tuning the memory hierarchy, and I/O enhancements to ensure scalability and efficiency across the compute, network, and storage systems that form the primary building blocks of a data center.
Growing Pains: The Challenge of Scale
The task of adding more cores and interconnecting them to create a multi-core data center processor may sound simple, but the interconnects between CPU cores, memory hierarchy, and I/O subsystems provide critical pathways among these subsystems necessitating thoughtful architecture. These interconnects are like a well-designed highway with the right number of lanes and ramps at critical places to allow traffic to flow smoothly rather than letting people and goods sit idle on the road without being productive.
Increasing the number of processor cores and raising the memory and I/O bandwidth per processor to service the demand for a wealth of data center workloads produces several challenges that must be addressed through creative architectural techniques. These challenges include:
• Increasing bandwidth between cores, on-chip cache hierarchy, memory controller, and I/O controllers. If the available interconnect bandwidth does not properly scale with other resources on the processor, then the interconnect becomes a bottleneck limiting system efficiency like a frustrating rush hour traffic jam.
• Reducing latency when accessing data from on-chip cache, main memory or other cores. The access latency is dependent on the distances between the chip entities, the path taken to send requests and responses, and the speed at which the interconnect operates. This is analogous to commute times in a spread out vs compact city, number of available routes, and the speed limit on the highways.
• Creating energy efficient ways to supply data to cores and I/O from on-chip cache and memory. Because of the larger distances and increased bandwidth requirements of each component, the amount of energy spent for the data movement to complete the same task goes up when more cores are added. In our traffic example, as a city grows and commute distances increase, the time and energy wasted during the commute leaves less resources available for productive work.
Intel is committed to innovating architectural solutions to stay ahead of these challenges in creating more powerful and efficient processors to meet the demands of established and emerging workloads such as artificial intelligence and deep learning.
Architecting the Data Center Processor of the Future
Intel has applied its experience and innovation in developing a new architecture for the upcoming Intel® Xeon® Scalable processors to provide a scalable foundation for the modern data center. This new architecture delivers a new way of interconnecting on-chip components to improve the efficiency and scalability of multi-core processors.
The Intel® Xeon® Scalable processors implement an innovative “mesh” on-chip interconnect topology that delivers low latency and high bandwidth among cores, memory, and I/O controllers. Figure 1 shows a representation of the mesh architecture where cores, on-chip cache banks, memory controllers, and I/O controllers are organized in rows and columns, with wires and switches connecting them at each intersection to allow for turns. By providing a more direct path than the prior ring architectures and many more pathways to eliminate bottlenecks, the mesh can operate at a lower frequency and voltage and can still deliver very high bandwidth and low latency. This results in improved performance and greater energy efficiency similar to a well-designed highway system that lets traffic flow at the optimal speed without congestion.
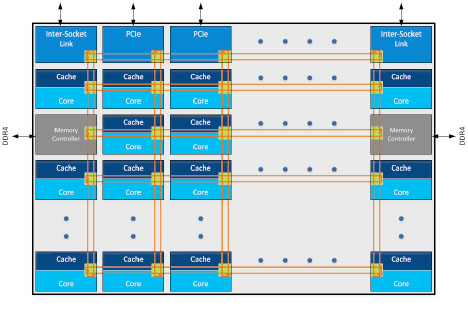
Figure 1: Mesh architecture conceptual representation
In addition to improving the connectivity and topology of the on-chip interconnect, the Intel® Xeon® Scalable processors also implement a modular architecture with scalable resources for accessing on-chip cache, memory, IO, and remote CPUs. These resources are distributed throughout the chip so “hot-spots” or other subsystem resource constraints are minimized. This modular and distributed aspect of the architecture allows available resources to scale as the number of processor cores increase.
The scalable and low-latency on-chip interconnect framework is also critical for the shared last level cache architecture. This large shared cache is valuable for complex multi-threaded server applications, such as databases, complex physical simulations, high-throughput networking applications, and for hosting multiple virtual machines. Negligible latency differences in accessing different cache banks allows software to treat the distributed cache banks as one large unified last level cache. As a result, application developers do not have to worry about variable latency in accessing different cache banks, nor do they need to optimize or recompile code to get a significant performance boosts out of their applications. The same benefit of uniform low latency accesses carry over to memory and IO accesses as well and a multi-threaded or distributed application with interaction between executions on different cores and data coming from IO devices need not have to carefully map cooperative threads on the core within a single socket to get optimal performance. As a result such applications can take advantage of larger number of cores and still achieve good scalability.
In Conclusion
The new architecture of the on-chip interconnect with a mesh topology provides a very powerful framework for integration of various components - cores, cache, memory, and I/O subsystem - of the Intel® Xeon® Scalable processors. This innovative architecture enables performance and efficiency improvements across the broadest variety of usage scenarios and provides the foundation for continued improvements by Intel and its unmatched global ecosystem to deliver solutions that provide the compute capacity and efficiency data center customers expect.







