





Texturing Performance
When looking at the texturing performance of a modern graphics processor and its associated board configuration, you want to look at a few key areas. The first is good old multitexture fillrate, or the ability for the GPU to maintain a large texture bandwidth even when working with many texture layers. While texture rate matters less than it used to, texture sampling is still absolutely required for modern rendering techniques.Multitexture Fillrate
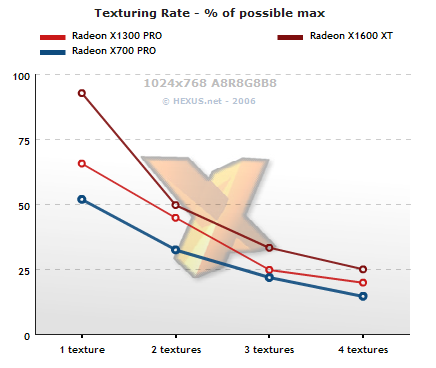
Sampling from a set of full-screen (1024x768) quads (8bpc, RGBA), we can see that the new RV5-class GPUs maintain closer to their theoretical maximums. Despite lower theoretical texturing rates due to having half the samplers. The new hardware is simply able to better issue texture fetch instructions so as to return the data faster.
RV515 stumbles when triple-texturing and the rates fall off in roughly the same way, when bandwidth limited, as the older hardware. The key thing to take from this is RV5xx's extra efficiency.
Floating Point Texture Bandwidth
Secondly, we measure available texture bandwidth by asking the hardware to read from sequential locations in an FP16 texture, the second texel sample relying on the first, creating a dependant texture read.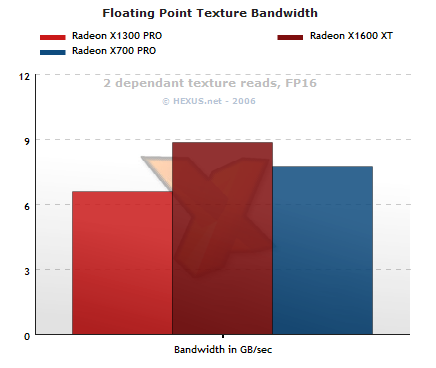
A whole class of rendering algorithms use dependant texture reads, so while not an outright test of the absolute maximum bandwidth, it's useful nonetheless. The results reflect the correlation between memory bandwidth and the ability and efficiency of the GPU's texture samplers. Despite a texel sampling deficit, RV530's efficiency and bandwidth advantage allow it to best X700 PRO, with the X1300 PRO not that far behind.
Texture Fetch Latency
Thirdly, there's texture fetch latency for a GPU to deal with. With fetches often taking hundreds of cycles, depending on the type of memory access needed and the location of the texels in memory, the GPU always tries to keep busy with other work while the fetch completes. So while the design of the GPU is such that fetches become as free as possible, as often as possible, calculating their latency is a worthwhile exercise.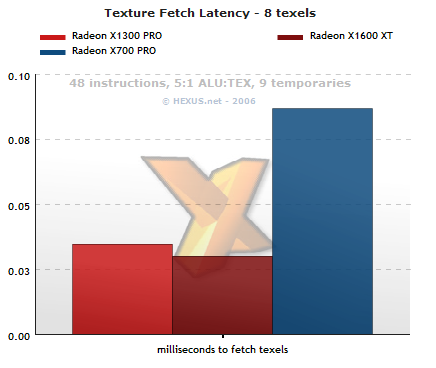
We fetch a small amount of texels using a short shader and no filtering. Don't be put off by the high-ish ALU:TEX ratio, since the difference is apparent even with a shorter shader and equal fetches.
It's not the time that's taken that's most important, rather the relative fetch latencies between chips is what to focus on. Since RV410 textures across its quads, it doesn't get any major advantage from having double the number of texture units, and RV515 and RV530 have the ability to fetch much quicker because of the separation of sampling from the shader ALUs when scheduling work to be done.



