





A Balancing Act
It's worth spending just a moment considering this ALU rebalancing as it has important ramifications for single-threaded performance. Now, like Intel, AMD can use four ALUs per thread, rather than the stunted two of Bulldozer, which was a bad design choice, so expect performance to be markedly better in this regard: our PiFast numbers will reveal all.
The queues have been enlarged, too, befitting a wider design. Putting it into numbers, the out-of-order load queue now supports 72 entries, up from 44, a Zen core can store 44 (up from 32) and retire 50 per cent more - 192 vs. 128. Keeping all this bubbling along is a double-wide micro-op retire. Point is, transistors have to be put down in the most efficient way for workloads of today and tomorrow, and by making Zen more efficient at the top end and wider in the middle, AMD boosts that all-important IPC metric. On the floating-point side, to the right, the biggest change is adding another pipe - four vs. three - to keep the beast fed.
Our first reaction to the per-core architecture is to look at critical-path analysis of exactly where Bulldozer stalled - and therefore couldn't be salvaged by an optimised redesign - and use those learnings for Zen. One can argue, successfully, that Zen, from a high-level core overview, looks much like a modern Intel CPU - higher IPC, micro-op cache, etc. - but that's no bad thing, is it?
Notice the last bit? It's important for huge multi-thread performance. As you may know, Zen features true simultaneous multi-threading (SMT).

We couldn't work out AMD's Bulldozer/Excavator strategy of pseudo SMT through what it called clustered multi-threading (CMT). It would only have made sense if software was specifically written for it, flying in the face of pervasive SMT, and one can only guess that having full-blown SMT was a stage too far for the rushed design. Perhaps it wanted to mitigate the risk by going for an easier version. After all, even Intel failed to have software properly optimised for its all-new Pentium 4 Netburst architecture, so what chance did AMD have with CMT?
AMD has realised that going against the tide made no sense for this clean-sheet architecture and, given enough time in the Zen design process, has therefore adopted an Intel-like hyperthreading of its own, for the first time. Mike Clark mentioned that a definite goal of SMT was to enable almost all of the design to be available in a single-thread mode, coloured red. SMT works most efficiently when it is able to run two threads through the core engine at the same time, making most sense in heavily-threaded applications such as Cinebench or Handbrake. The high-level architecture, again, looks like Intel's, and the uplift from running another thread at the same time is up to 41 per cent. There is a cost to going down this route, namely increased power consumption, additional transistors required to make SMT work, and the need for an excellent caching system, which leads us nicely on to the next point: caches.
Caching in
Another aspect where Bulldozer failed to live up to expectations was with respect to the efficiency of its caching structure, and this was clearly an area where AMD needed to work on. There have been manifest changes. Speed is important as caches are closer to the CPU. Zen's L1 and L2 caches are significantly faster than, you're probably bored of hearing it, the previous Bulldozer/Excavator generation. Mike Clark mentioned a speed-up of 2x. Another fundamental change is that L1 is now a simpler write-back cache, not write-through, which means that it reduces the penalty for read misses from two accesses to one. Augmenting these is a better data prefetcher.
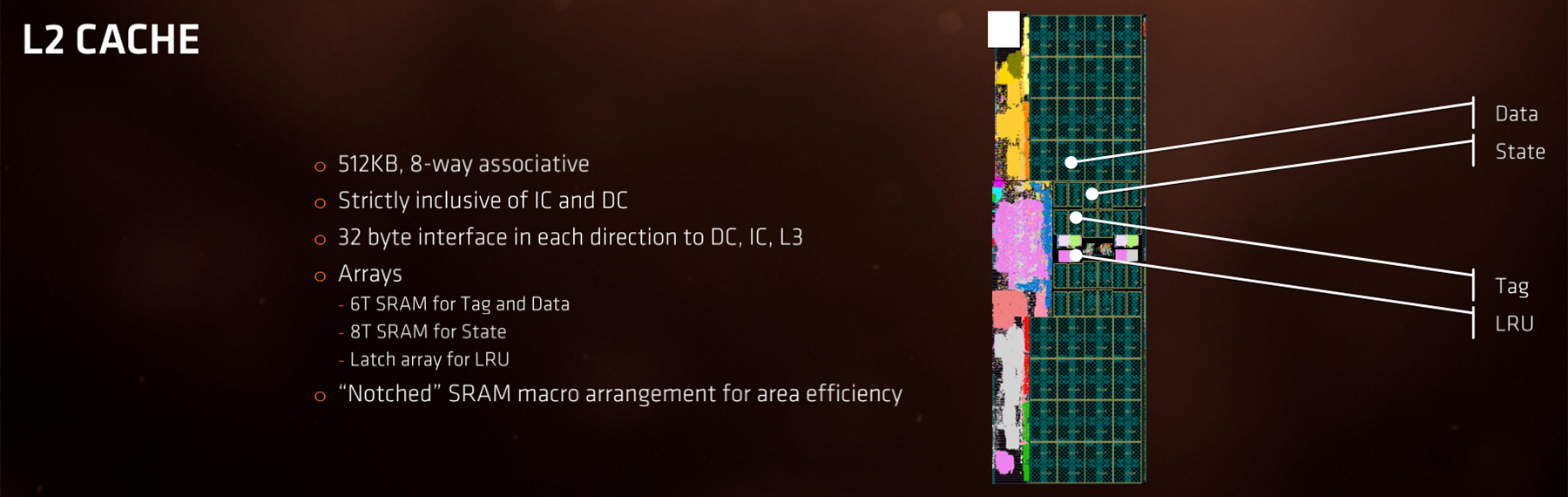

The L3 cache now runs at the speed of the fastest core, or about twice the speed of Bulldozer. Second, in an effort to boost latency from the caches, Zen uses 16-way associativity (like Intel) instead of 64-way. Sure, having more associativity means there is a better chance of finding the data the CPU needs to work on, but searching throughout a super-associated cache is painful in terms of time and latency. Zen's L3 is much faster and a bit 'looser', and it also performs as a victim cache for L1 and L2, meaning, quite literally, it holds data evicted by them. Zen is supposed to have an overall peak 5x L3 speed improvement over Bulldozer.
Holding It Together: the CCX
Now we know about the core and caches. The next step is to build out Zen into what AMD terms CPU Complexes (CCX). What we see is that a single CCX holds four cores, 2MB of L2 cache (4x512KB), and 8MB of L3, split into four 2MB slices. As is normal these days, each core has access to its own, dedicated L2 cache but all can jump on the same L3 cache, at the same speed and latency.

This means the premium Ryzen processors, comprising eight cores and 16 threads, are actually two CCX Complexes glued together through a new, proprietary interconnect called Infinity Fabric. The latency implications of traversing this fabric are not known, though AMD has previously said that it's minimal. Interestingly, the CCXes form a system-on-chip (SoC), meaning that they integrate the dual-channel memory controller, 'chipset', and PCIe routing. This should make motherboard design simpler but also less partial to performance optimisations from the likes of Asus and MSI.
Architecture Summary
We've laboured the point, perhaps excessively so, that Zen takes many leaves out of the Intel architecture playbook. This is no bad thing, of course, and AMD adds liberal sprinkles of its own mojo into the mix. Should frequencies be up to scratch, Zen looks like a formidable multi-core engine in both the consumer and, more pertinently perhaps, server and workstation environments.



